
该项目用于在 Flink 中为流处理和批处理构建动态表,支持超大流量的数据提取和及时的数据查询。
注意:该项目仍处于 beta 状态,正在快速发展,不建议直接在生产环境中使用它。
Flink Table Store 介绍
在过去的几年里,得益于 Flink 社区众多的贡献者和用户,Apache Flink 已经成为最好的分布式计算引擎之一,尤其是在大规模有状态流处理方面。然而,当人们试图从他们的数据中实时获取洞察力时,仍然面临着一些挑战。在这些挑战中,一个突出的问题是缺乏满足所有计算模式的存储。
到目前为止,我们通常会部署一些存储系统来与 Flink 一起用于不同目的是很常见的。典型的设置是用于流处理的消息队列、用于批处理和即席查询的可查询文件系统/对象存储,以及用于查找的 K-V 存储。由于其复杂性和异构性,这种架构在数据质量和系统维护方面提出了挑战。这正在成为影响 Apache Flink 带来的流批统一端到端用户体验的一大问题。
Flink Table Store 的目标就是解决上述问题,这是该项目的重要一步。它将 Flink 的能力从计算扩展到存储领域。 因此,我们可以为用户提供更好的端到端体验。
Flink Table Store 旨在提供统一的存储抽象,让用户不必自己构建混合存储。具体来说,Flink Table Store 提供以下核心能力:
支持超大数据集的存储,并允许以批处理和流方式读取和写入
支持毫秒级别延迟的流式查询
支持秒级别延迟的 Batch/OLAP 查询
默认支持流读增量快照,所以用户不需要自己解决组合不同存储的问题
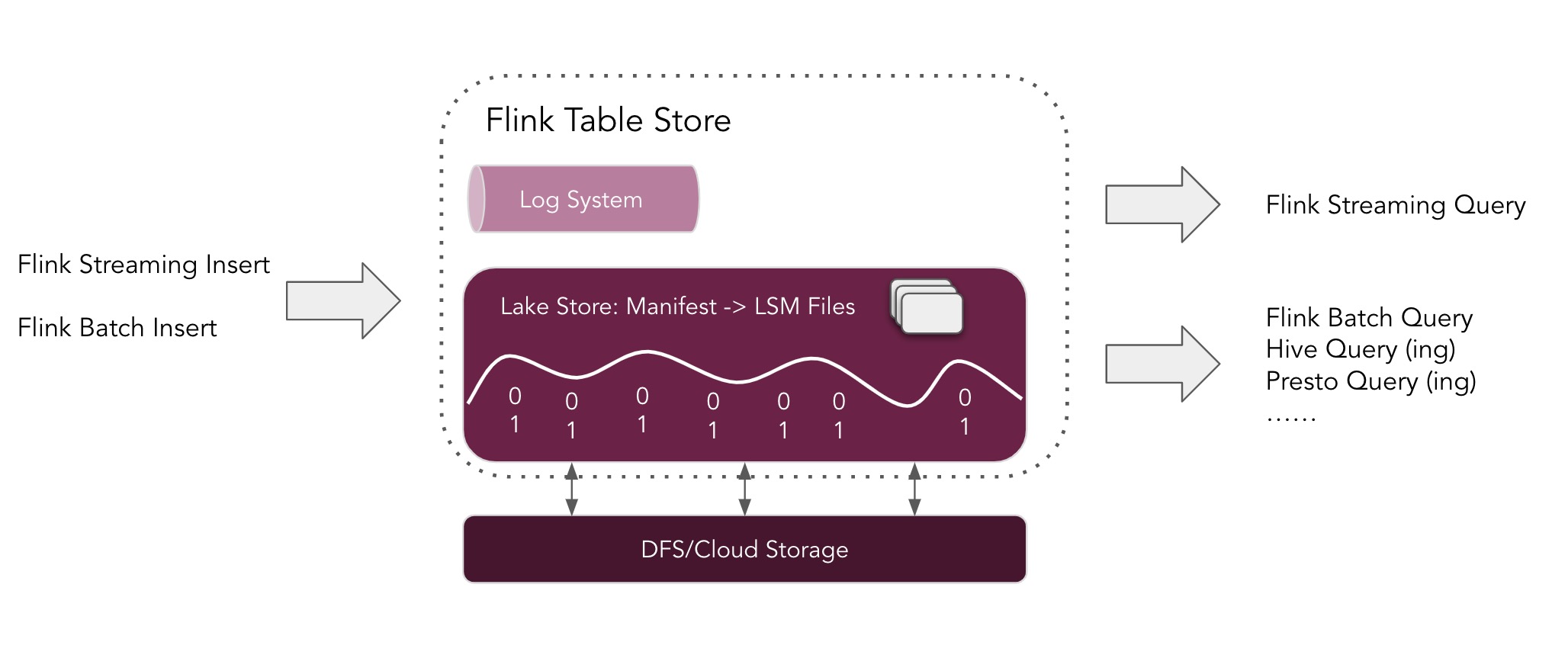
在这个版本中,架构如上图所示:
用户可以使用 Flink 将数据写入到 Table Store 中,既可以通过流式将数据库中捕获的变更日志写入,也可以通过从数据仓库等其他存储中批量加载数据后再写入
用户可以使用 Flink 以不同的方式查询 Table Store,包括流式查询和 Batch/OLAP 查询。 还值得注意的是,用户也可以使用其他引擎(例如 Apache Hive)从 Table Store 中查询
在底层,Table Store 使用混合存储架构,使用 Lake Store 存储历史数据,使用 Queue 系统(目前支持 Apache Kafka 集成)存储增量数据。 它为混合流式读取提供增量快照
Table Store 的 Lake Store 将数据作为列文件存储在文件系统/对象存储上,并使用 LSM 结构来支持大量的数据更新和高性能查询
非常感谢以下系统的启发:Apache Iceberg 和 RocksDB。
后续进展
社区目前正在努力强化核心逻辑,稳定存储格式等,以使 Flink Table Store 可以投入生产。
在即将发布的 0.2.0 版本中,可以期待(至少)以下功能:
生态:支持 Apache Hive Engine 的 Flink Table Store Reader
核心:支持自适应 Bucket 数量
核心:支持仅 append 的数据,Table Store 不仅仅局限于更新场景
核心:完善的 schema 变化
改进基于预览版得到的反馈
从中期来看,你还可以期待:
生态系统:支持 Trino、PrestoDB 和 Apache Spark 的 Flink Table Store Reader
Flink Table Store Service 会加速更新,提升查询性能
尝鲜
可以通过 https://nightlies.apache.org/flink/flink-table-store-docs-release-0.1/docs/try-table-store/quick-start/ 来尝试一下。
下载链接:https://flink.apache.org/downloads.html
翻译原文链接:https://flink.apache.org/news/2022/05/11/release-table-store-0.1.0.html
原文作者:李劲松 & 秦江杰



