
Apache Flink 是一个面向分布式数据流处理和批量数据处理的开源计算平台,它能够基于同一个 Flink 运行时,提供支持流处理和批处理两种类型应用的功能。
本文转载自博客园,作者:Florian
原文地址:
https://www.cnblogs.com/fanzhidongyzby/p/6297723.html
现有的开源计算方案,会把流处理和批处理作为两种不同的应用类型,因为它们所提供的 SLA(Service-Level-Aggreement)是完全不相同的:流处理一般需要支持低延迟、Exactly-once 保证,而批处理需要支持高吞吐、高效处理。
Flink 从另一个视角看待流处理和批处理,将二者统一起来:Flink 是完全支持流处理,也就是说作为流处理看待时输入数据流是无界的;批处理被作为一种特殊的流处理,只是它的输入数据流被定义为有界的。
Flink 流处理特性:
支持高吞吐、低延迟、高性能的流处理
支持带有事件时间的窗口(Window)操作
支持有状态计算的 Exactly-once 语义
支持高度灵活的窗口(Window)操作,支持基于 time、count、session,以及 data-driven 的窗口操作
支持具有 Backpressure 功能的持续流模型
支持基于轻量级分布式快照(Snapshot)实现的容错
一个运行时同时支持 Batch on Streaming 处理和 Streaming 处理
Flink 在 JVM 内部实现了自己的内存管理
支持迭代计算
支持程序自动优化:避免特定情况下 Shuffle、排序等昂贵操作,中间结果有必要进行缓存
一、架构
Flink 以层级式系统形式组件其软件栈,不同层的栈建立在其下层基础上,并且各层接受程序不同层的抽象形式。
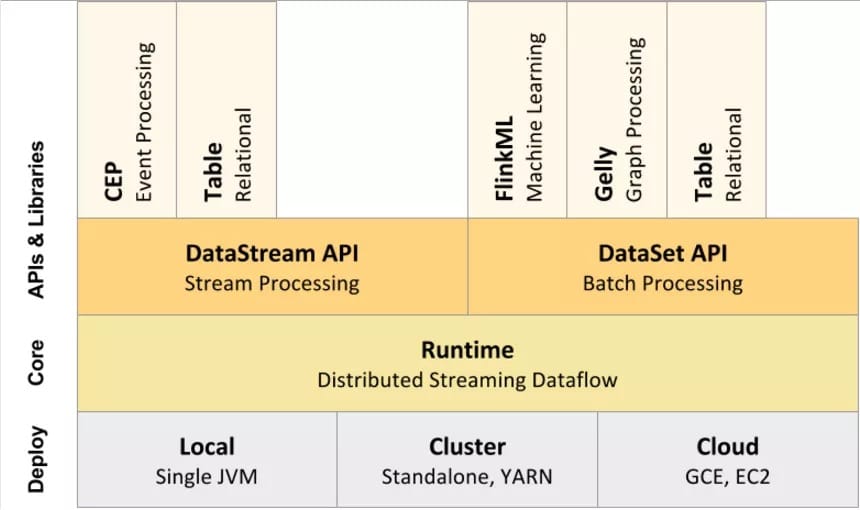
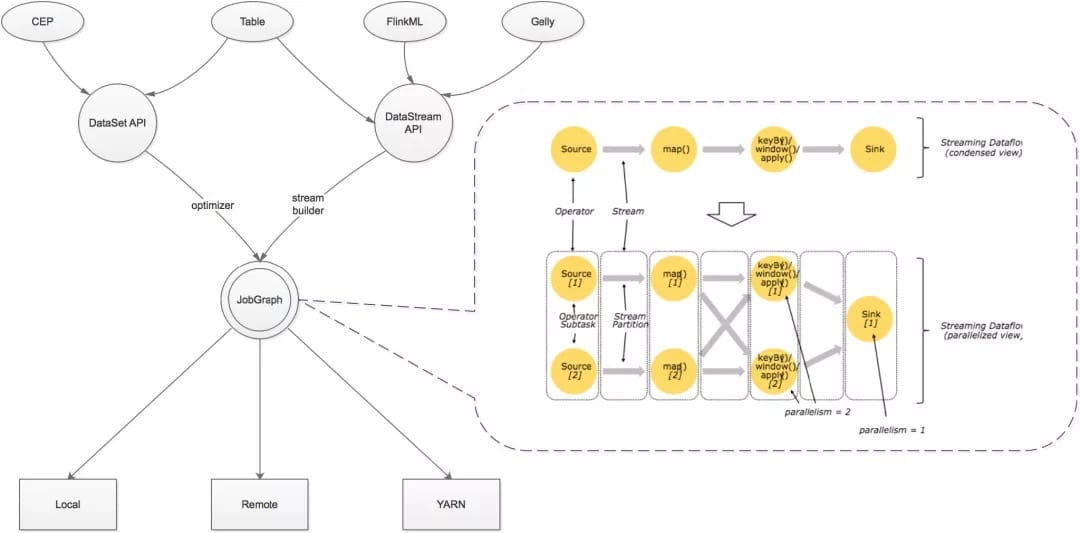
1、运行时层以 JobGraph 形式接收程序。JobGraph 即为一个一般化的并行数据流图(data flow),它拥有任意数量的 Task 来接收和产生 data stream。
2、DataStream API 和 DataSet API 都会使用单独编译的处理方式生成 JobGraph。DataSet API 使用optimizer 来决定针对程序的优化方法,而 DataStream API 则使用 stream builder 来完成该任务。
3、在执行 JobGraph 时,Flink 提供了多种候选部署方案(如 local,remote,YARN 等)。
4、Flink 附随了一些产生 DataSet 或 DataStream API 程序的的类库和 API:处理逻辑表查询的 Table,机器学习的 FlinkML,图像处理的 Gelly,复杂事件处理的 CEP。
二、原理
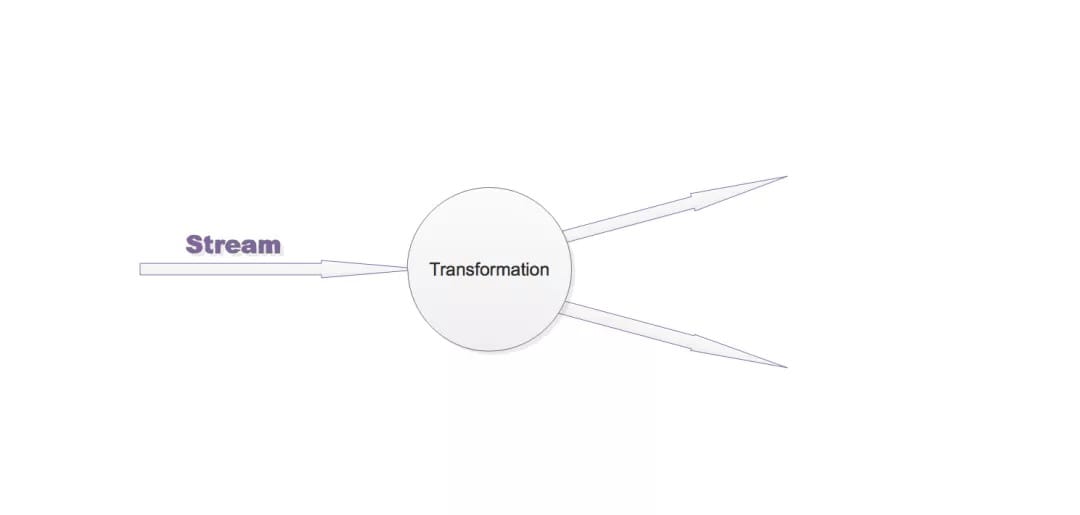
1. 流、转换、操作符
Flink 程序是由 Stream 和 Transformation 这两个基本构建块组成,其中 Stream 是一个中间结果数据,而Transformation 是一个操作,它对一个或多个输入 Stream 进行计算处理,输出一个或多个结果 Stream。
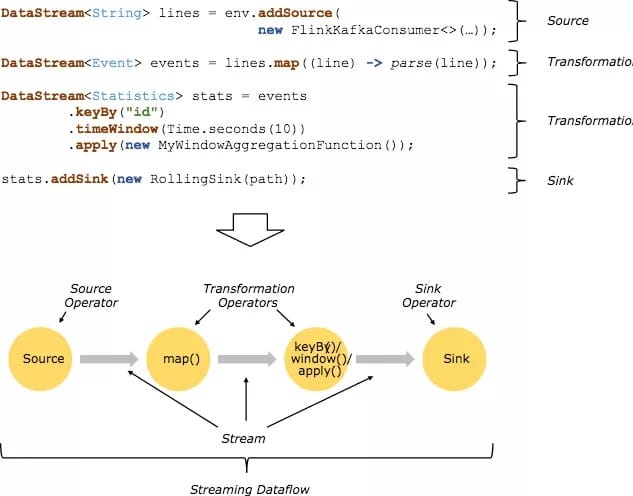
Flink 程序被执行的时候,它会被映射为 Streaming Dataflow。一个 Streaming Dataflow 是由一组 Stream 和Transformation Operator 组成,它类似于一个 DAG 图,在启动的时候从一个或多个 Source Operator 开始,结束于一个或多个 Sink Operator。
2. 并行数据流
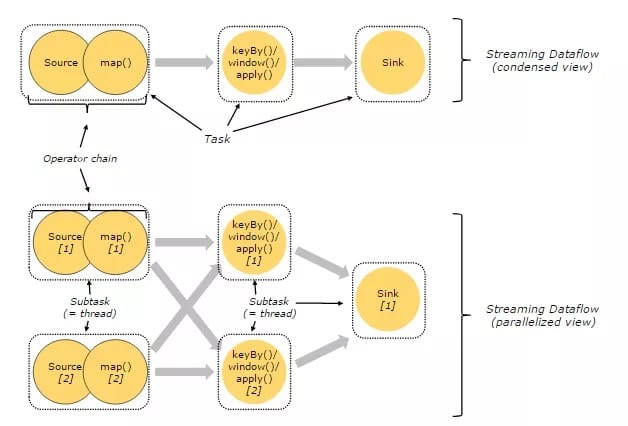
一个 Stream 可以被分成多个 Stream 分区(Stream Partitions),一个 Operator 可以被分成多个 Operator Subtask,每一个 Operator Subtask 是在不同的线程中独立执行的。一个 Operator 的并行度,等于 Operator Subtask 的个数,一个 Stream 的并行度总是等于生成它的 Operator 的并行度。

One-to-one 模式
比如从 Source[1] 到 map()[1],它保持了 Source 的分区特性(Partitioning)和分区内元素处理的有序性,也就是说 map()[1] 的 Subtask 看到数据流中记录的顺序,与 Source[1] 中看到的记录顺序是一致的。
Redistribution模式
这种模式改变了输入数据流的分区,比如从 map()[1]、map()[2] 到 keyBy()/window()/apply()[1]、keyBy()/window()/apply()[2],上游的 Subtask 向下游的多个不同的 Subtask 发送数据,改变了数据流的分区,这与实际应用所选择的 Operator 有关系。
3. 任务、操作符链
Flink 分布式执行环境中,会将多个 Operator Subtask 串起来组成一个 Operator Chain,实际上就是一个执行链,每个执行链会在 TaskManager 上一个独立的线程中执行。
4. 时间
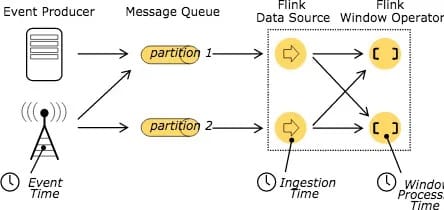
处理 Stream 中的记录时,记录中通常会包含各种典型的时间字段:
Event Time:表示事件创建时间
Ingestion Time:表示事件进入到 Flink Dataflow 的时间
Processing Time:表示某个 Operator 对事件进行处理的本地系统时间
Flink 使用 WaterMark 衡量时间的时间,WaterMark 携带时间戳 t,并被插入到 stream 中。
WaterMark 的含义是所有时间 t’< t 的事件都已经发生。
针对乱序的的流,WaterMark 至关重要,这样可以允许一些事件到达延迟,而不至于过于影响 window 窗口的计算。
并行数据流中,当 Operator 有多个输入流时,Operator 的 event time 以最小流 event time 为准。

5. 窗口
Flink 支持基于时间窗口操作,也支持基于数据的窗口操作:

窗口分类:
按分割标准划分:timeWindow、countWindow
按窗口行为划分:Tumbling Window、Sliding Window、自定义窗口
Tumbling/Sliding Time Window
1 | // Stream of (sensorId, carCnt) |
Tumbling/Sliding Count Window
1 | // Stream of (sensorId, carCnt) |
自定义窗口
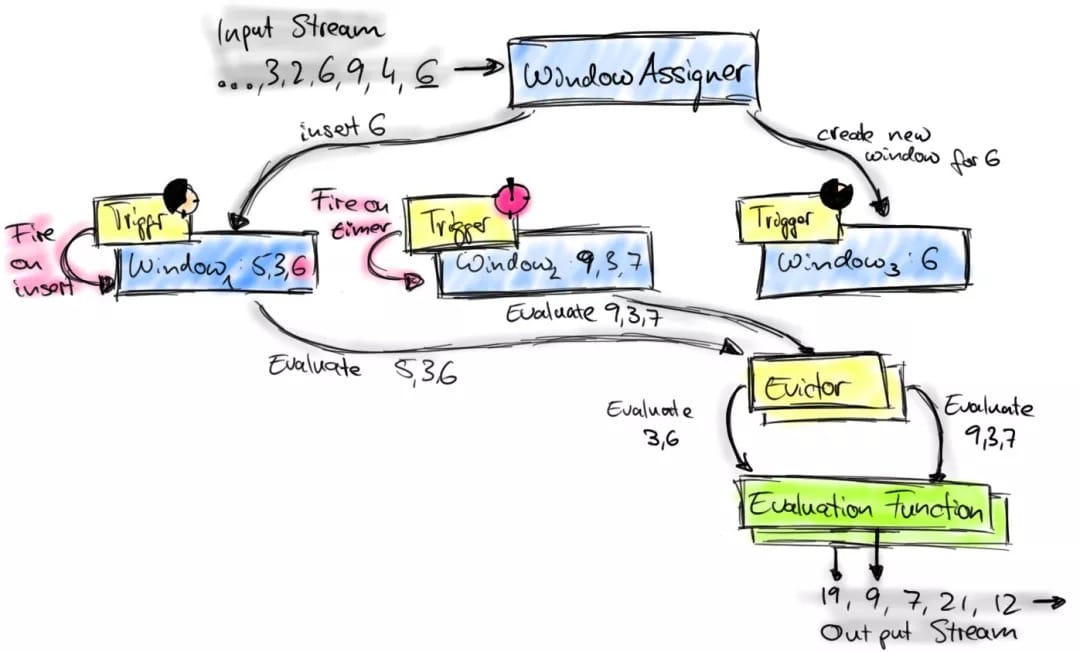
基本操作:
window:创建自定义窗口
trigger:自定义触发器
evictor:自定义evictor
apply:自定义window function
6. 容错
Barrier 机制:
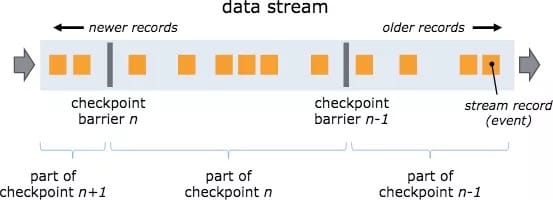
出现一个 Barrier,在该 Barrier 之前出现的记录都属于该 Barrier 对应的 Snapshot,在该 Barrier 之后出现的记录属于下一个 Snapshot。
来自不同Snapshot多个Barrier可能同时出现在数据流中,也就是说同一个时刻可能并发生成多个Snapshot。
当一个中间(Intermediate)Operator接收到一个Barrier后,它会发送Barrier到属于该Barrier的Snapshot的数据流中,等到Sink Operator接收到该Barrier后会向Checkpoint Coordinator确认该Snapshot,直到所有的Sink Operator都确认了该Snapshot,才被认为完成了该Snapshot。
对齐:
当Operator接收到多个输入的数据流时,需要在Snapshot Barrier中对数据流进行排列对齐:
Operator从一个incoming Stream接收到Snapshot Barrier n,然后暂停处理,直到其它的incoming Stream的Barrier n(否则属于2个Snapshot的记录就混在一起了)到达该Operator
接收到Barrier n的Stream被临时搁置,来自这些Stream的记录不会被处理,而是被放在一个Buffer中。
一旦最后一个Stream接收到Barrier n,Operator会emit所有暂存在Buffer中的记录,然后向Checkpoint Coordinator发送Snapshot n。
继续处理来自多个Stream的记录
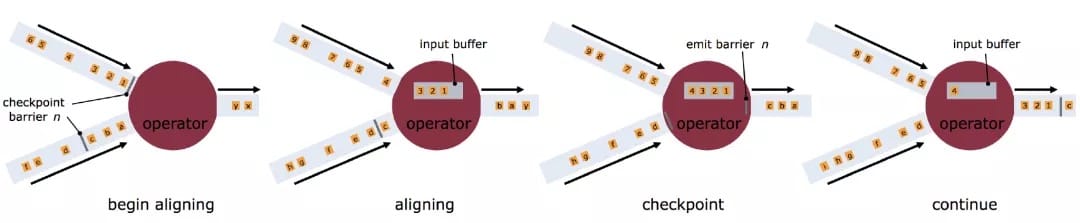
基于Stream Aligning操作能够实现Exactly Once语义,但是也会给流处理应用带来延迟,因为为了排列对齐Barrier,会暂时缓存一部分Stream的记录到Buffer中,尤其是在数据流并行度很高的场景下可能更加明显,通常以最迟对齐Barrier的一个Stream为处理Buffer中缓存记录的时刻点。在Flink中,提供了一个开关,选择是否使用Stream Aligning,如果关掉则Exactly Once会变成At least once。
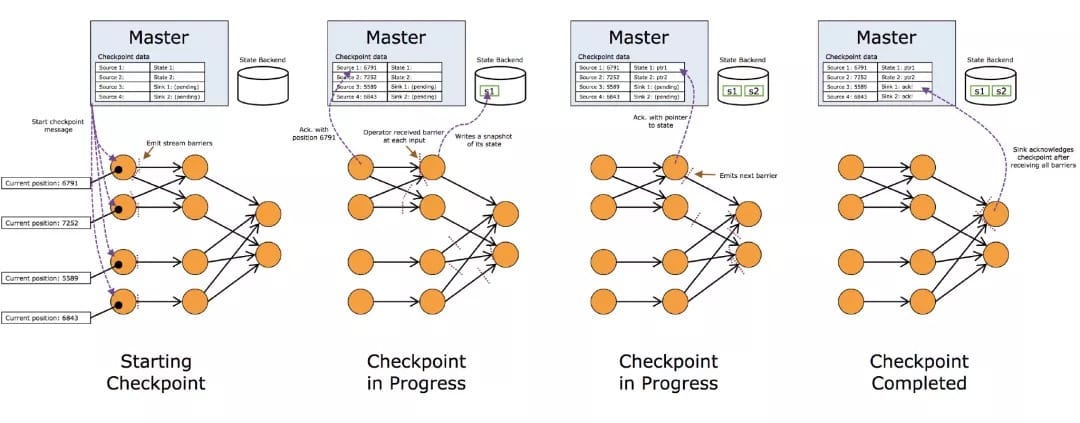
CheckPoint:
Snapshot并不仅仅是对数据流做了一个状态的Checkpoint,它也包含了一个Operator内部所持有的状态,这样才能够在保证在流处理系统失败时能够正确地恢复数据流处理。状态包含两种:
系统状态:一个Operator进行计算处理的时候需要对数据进行缓冲,所以数据缓冲区的状态是与Operator相关联的。以窗口操作的缓冲区为例,Flink系统会收集或聚合记录数据并放到缓冲区中,直到该缓冲区中的数据被处理完成。
一种是用户自定义状态(状态可以通过转换函数进行创建和修改),它可以是函数中的Java对象这样的简单变量,也可以是与函数相关的Key/Value状态。
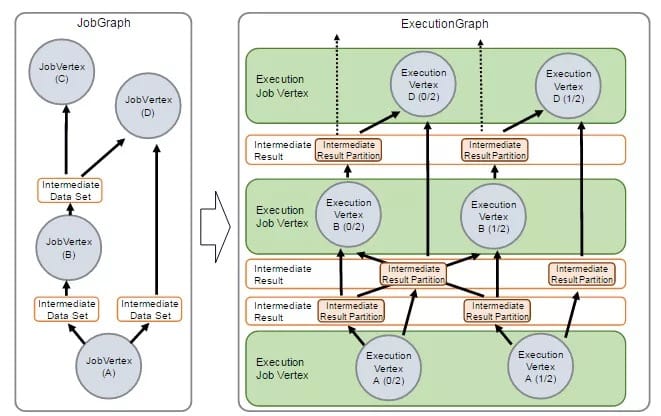
7. 调度
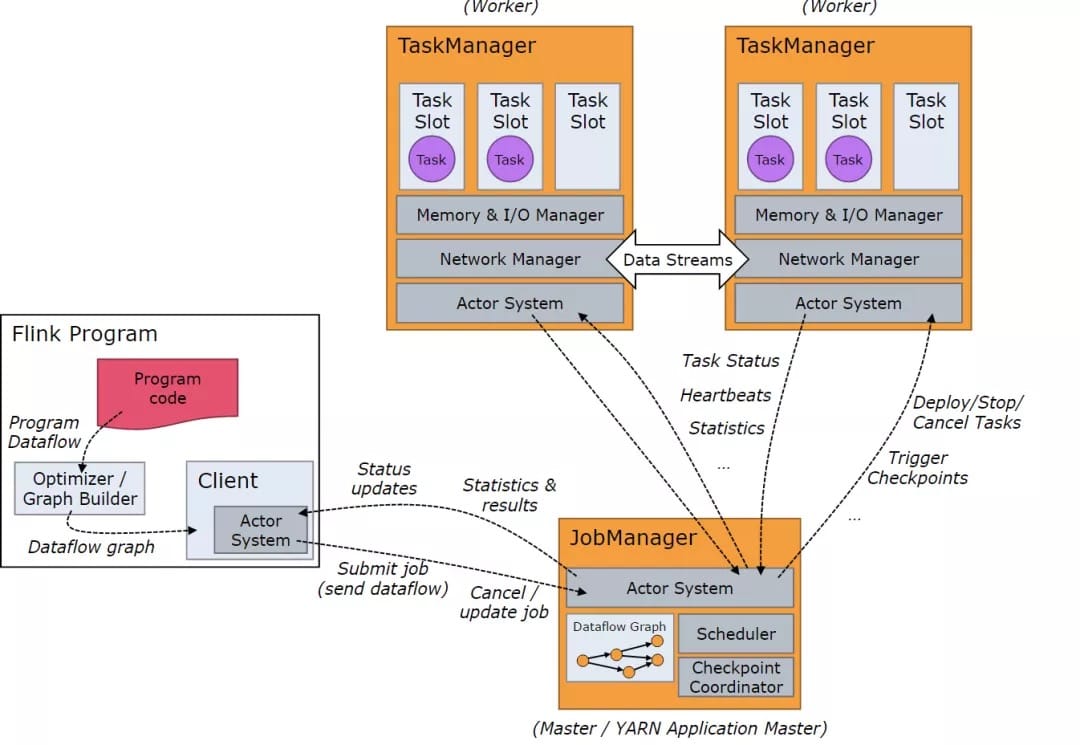
在JobManager端,会接收到Client提交的JobGraph形式的Flink Job,JobManager会将一个JobGraph转换映射为一个ExecutionGraph,ExecutionGraph是JobGraph的并行表示,也就是实际JobManager调度一个Job在TaskManager上运行的逻辑视图。
物理上进行调度,基于资源的分配与使用的一个例子:
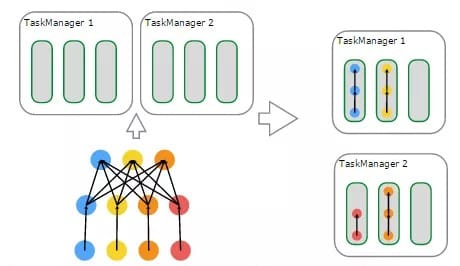
左上子图:有2个TaskManager,每个TaskManager有3个Task Slot
左下子图:一个Flink Job,逻辑上包含了1个data source、1个MapFunction、1个ReduceFunction,对应一个JobGraph
左下子图:用户提交的Flink Job对各个Operator进行的配置——data source的并行度设置为4,MapFunction的并行度也为4,ReduceFunction的并行度为3,在JobManager端对应于ExecutionGraph
右上子图:TaskManager 1上,有2个并行的ExecutionVertex组成的DAG图,它们各占用一个Task Slot
右下子图:TaskManager 2上,也有2个并行的ExecutionVertex组成的DAG图,它们也各占用一个Task Slot
在2个TaskManager上运行的4个Execution是并行执行的
8. 迭代
机器学习和图计算应用,都会使用到迭代计算,Flink通过在迭代Operator中定义Step函数来实现迭代算法,这种迭代算法包括Iterate和Delta Iterate两种类型。
Iterate
Iterate Operator是一种简单的迭代形式:每一轮迭代,Step函数的输入或者是输入的整个数据集,或者是上一轮迭代的结果,通过该轮迭代计算出下一轮计算所需要的输入(也称为Next Partial Solution),满足迭代的终止条件后,会输出最终迭代结果。

流程伪代码:
1 | IterationState state = getInitialState(); |
Delta Iterate
Delta Iterate Operator实现了增量迭代。
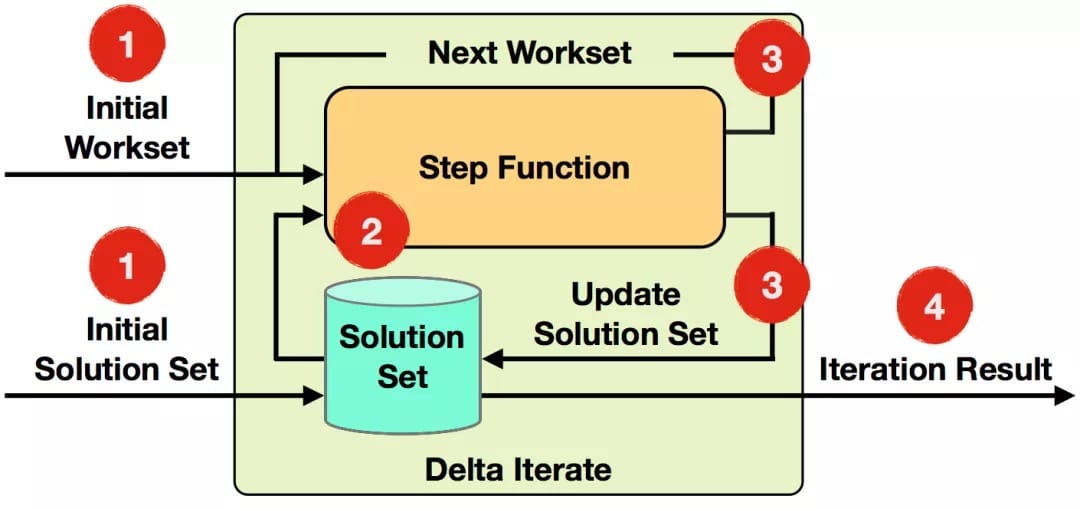
流程伪代码:
1 | IterationState workset = getInitialState(); |
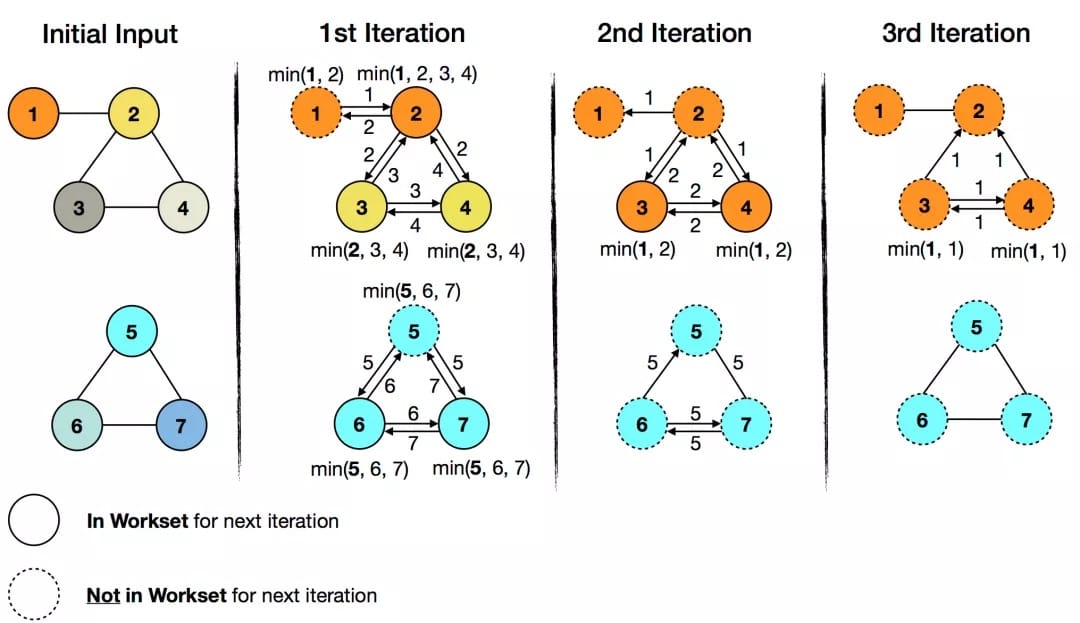
最小值传播:
9. Back Pressure监控
流处理系统中,当下游Operator处理速度跟不上的情况,如果下游Operator能够将自己处理状态传播给上游Operator,使得上游Operator处理速度慢下来就会缓解上述问题,比如通过告警的方式通知现有流处理系统存在的问题。
Flink Web界面上提供了对运行Job的Backpressure行为的监控,它通过使用Sampling线程对正在运行的Task进行堆栈跟踪采样来实现。
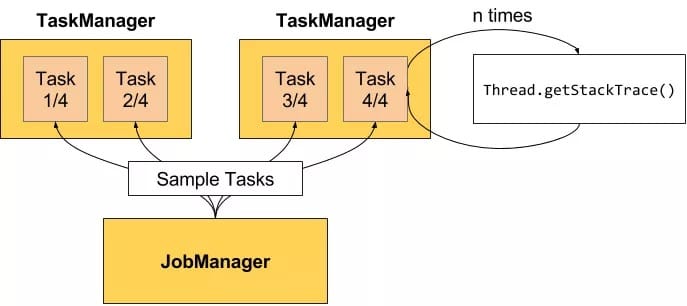
默认情况下,JobManager会每间隔50ms触发对一个Job的每个Task依次进行100次堆栈跟踪调用,过计算得到一个比值,例如,radio=0.01,表示100次中仅有1次方法调用阻塞。Flink目前定义了如下Backpressure状态:
OK: 0 <= Ratio <= 0.10
LOW: 0.10 < Ratio <= 0.5
HIGH: 0.5 < Ratio <= 1
三、库
1. Table
Flink的Table API实现了使用类SQL进行流和批处理。
详情参考:https://ci.apache.org/projects/flink/flink-docs-release-1.2/dev/table_api.html
2. CEP
Flink的CEP(Complex Event Processing)支持在流中发现复杂的事件模式,快速筛选用户感兴趣的数据。
3. Gelly
Gelly是Flink提供的图计算API,提供了简化开发和构建图计算分析应用的接口。
详情参考:https://ci.apache.org/projects/flink/flink-docs-release-1.2/dev/libs/gelly/index.html
4. FlinkML
FlinkML是Flink提供的机器学习库,提供了可扩展的机器学习算法、简洁的API和工具简化机器学习系统的开发。
详情参考:https://ci.apache.org/projects/flink/flink-docs-release-1.2/dev/libs/ml/index.html
四、部署
当Flink系统启动时,首先启动JobManager和一至多个TaskManager。JobManager负责协调Flink系统,TaskManager则是执行并行程序的worker。当系统以本地形式启动时,一个JobManager和一个TaskManager会启动在同一个JVM中。
当一个程序被提交后,系统会创建一个Client来进行预处理,将程序转变成一个并行数据流的形式,交给JobManager和TaskManager执行。
1. 启动测试
编译flink,本地启动。
1 | $ java -version |
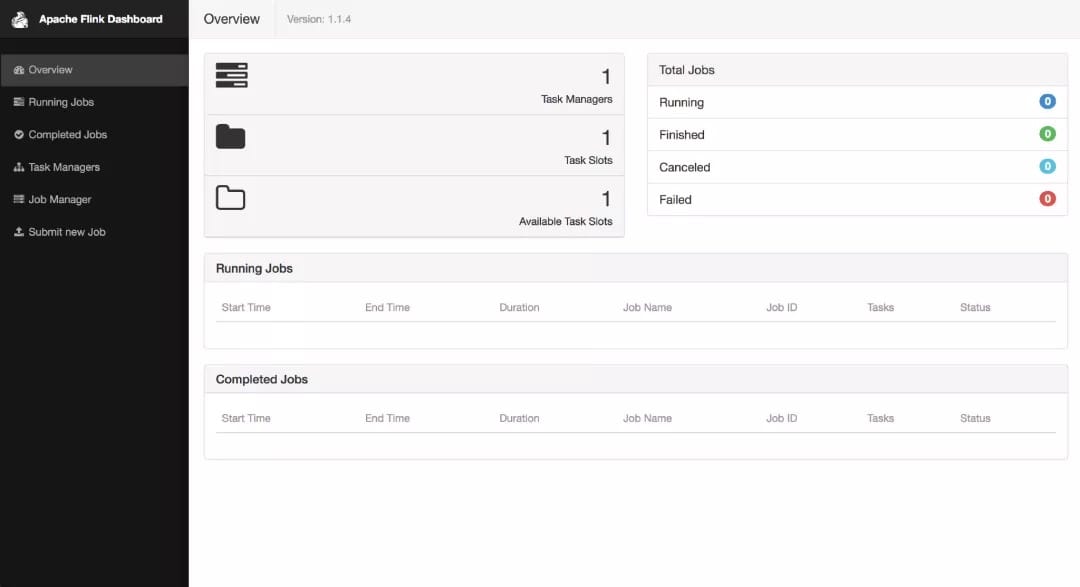
编写本地流处理demo。
SocketWindowWordCount.java
1 | public class SocketWindowWordCount { |
pom.xml
1 | <!-- Use this dependency if you are using the DataStream API --> |
执行mvn构建。
1 | mvn clean install |
开启9000端口,用于输入数据:
1 | $ nc -l 9000 |
提交flink任务:
1 | $ ./bin/flink run -c com.demo.florian.WordCount $DEMO_DIR/target/flink-demo-1.0-SNAPSHOT.jar --port 9000 |
在nc里输入数据后,查看执行结果:
1 | $ tail -f log/flink-*-jobmanager-*.out |
查看flink web页面:localhost:8081

2. 代码结构
Flink系统核心可分为多个子项目。分割项目旨在减少开发Flink程序需要的依赖数量,并对测试和开发小组件提供便捷。
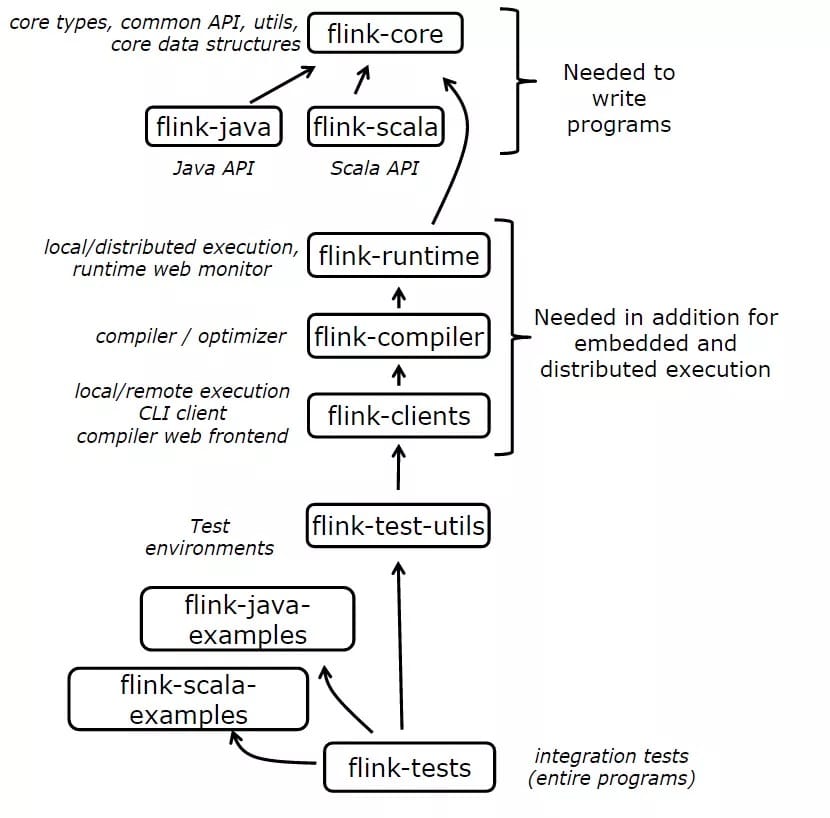
Flink当前还包括以下子项目:
Flink-dist:distribution项目。它定义了如何将编译后的代码、脚本和其他资源整合到最终可用的目录结构中。
Flink-quick-start:有关quickstart和教程的脚本、maven原型和示例程序
flink-contrib:一系列有用户开发的早起版本和有用的工具的项目。后期的代码主要由外部贡献者继续维护,被flink-contirb接受的代码的要求低于其他项目的要求。
3. Flink On YARN
Flink在YARN集群上运行时:Flink YARN Client负责与YARN RM通信协商资源请求,Flink JobManager和Flink TaskManager分别申请到Container去运行各自的进程。
YARN AM与Flink JobManager在同一个Container中,这样AM可以知道Flink JobManager的地址,从而AM可以申请Container去启动Flink TaskManager。待Flink成功运行在YARN集群上,Flink YARN Client就可以提交Flink Job到Flink JobManager,并进行后续的映射、调度和计算处理。
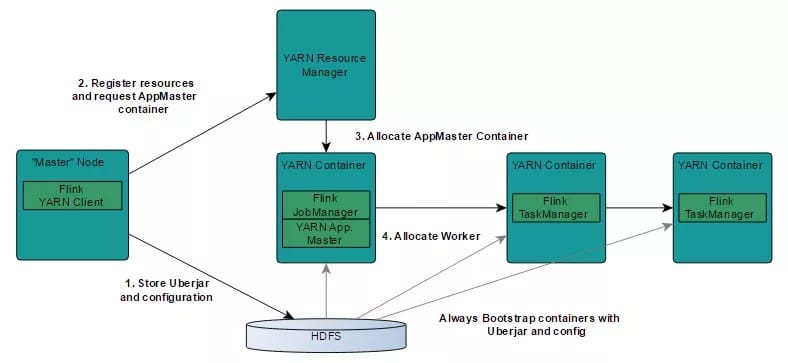
1、设置Hadoop环境变量
1 | $ export HADOOP_CONF_DIR=/etc/hadoop/conf |
2、以集群模式提交任务,每次都会新建flink集群
1 | $ ./bin/flink run -m yarn-cluster -c com.demo.florian.WordCount $DEMO_DIR/target/flink-demo-1.0-SNAPSHOT.jar |
3、启动共享flink集群,提交任务
1 | $ ./bin/yarn-session.sh -n 4 -jm 1024 -tm 4096 -d |
###参考资料
http://shiyanjun.cn/archives/1508.html
https://ci.apache.org/projects/flink/flink-docs-release-1.2/index.html
最后
GitHub Flink 学习代码地址:https://github.com/zhisheng17/flink-learning
微信公众号:zhisheng
另外我自己整理了些 Flink 的学习资料,目前已经全部放到微信公众号(zhisheng)了,你可以回复关键字:Flink 即可无条件获取到。另外也可以加我微信 你可以加我的微信:yuanblog_tzs,探讨技术!

更多私密资料请加入知识星球!

专栏介绍
首发地址:http://www.54tianzhisheng.cn/2019/11/15/flink-in-action/
专栏地址:https://gitbook.cn/gitchat/column/5dad4a20669f843a1a37cb4f
博客
1、Flink 从0到1学习 —— Apache Flink 介绍
2、Flink 从0到1学习 —— Mac 上搭建 Flink 1.6.0 环境并构建运行简单程序入门
3、Flink 从0到1学习 —— Flink 配置文件详解
4、Flink 从0到1学习 —— Data Source 介绍
5、Flink 从0到1学习 —— 如何自定义 Data Source ?
6、Flink 从0到1学习 —— Data Sink 介绍
7、Flink 从0到1学习 —— 如何自定义 Data Sink ?
8、Flink 从0到1学习 —— Flink Data transformation(转换)
9、Flink 从0到1学习 —— 介绍 Flink 中的 Stream Windows
10、Flink 从0到1学习 —— Flink 中的几种 Time 详解
11、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 ElasticSearch
12、Flink 从0到1学习 —— Flink 项目如何运行?
13、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 Kafka
14、Flink 从0到1学习 —— Flink JobManager 高可用性配置
15、Flink 从0到1学习 —— Flink parallelism 和 Slot 介绍
16、Flink 从0到1学习 —— Flink 读取 Kafka 数据批量写入到 MySQL
17、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 RabbitMQ
18、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 HBase
19、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 HDFS
20、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 Redis
21、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 Cassandra
22、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 Flume
23、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 InfluxDB
24、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 RocketMQ
25、Flink 从0到1学习 —— 你上传的 jar 包藏到哪里去了
26、Flink 从0到1学习 —— 你的 Flink job 日志跑到哪里去了
28、Flink 从0到1学习 —— Flink 中如何管理配置?
29、Flink 从0到1学习—— Flink 不可以连续 Split(分流)?
30、Flink 从0到1学习—— 分享四本 Flink 国外的书和二十多篇 Paper 论文
32、为什么说流处理即未来?
33、OPPO 数据中台之基石:基于 Flink SQL 构建实时数据仓库
36、Apache Flink 结合 Kafka 构建端到端的 Exactly-Once 处理
38、如何基于Flink+TensorFlow打造实时智能异常检测平台?只看这一篇就够了
40、Flink 全网最全资源(视频、博客、PPT、入门、原理、实战、性能调优、源码解析、问答等持续更新)
42、Flink 从0到1学习 —— 如何使用 Side Output 来分流?
源码解析
4、Flink 源码解析 —— standalone session 模式启动流程
5、Flink 源码解析 —— Standalone Session Cluster 启动流程深度分析之 Job Manager 启动
6、Flink 源码解析 —— Standalone Session Cluster 启动流程深度分析之 Task Manager 启动
7、Flink 源码解析 —— 分析 Batch WordCount 程序的执行过程
8、Flink 源码解析 —— 分析 Streaming WordCount 程序的执行过程
9、Flink 源码解析 —— 如何获取 JobGraph?
10、Flink 源码解析 —— 如何获取 StreamGraph?
11、Flink 源码解析 —— Flink JobManager 有什么作用?
12、Flink 源码解析 —— Flink TaskManager 有什么作用?
13、Flink 源码解析 —— JobManager 处理 SubmitJob 的过程
14、Flink 源码解析 —— TaskManager 处理 SubmitJob 的过程
15、Flink 源码解析 —— 深度解析 Flink Checkpoint 机制
16、Flink 源码解析 —— 深度解析 Flink 序列化机制
17、Flink 源码解析 —— 深度解析 Flink 是如何管理好内存的?
18、Flink Metrics 源码解析 —— Flink-metrics-core
19、Flink Metrics 源码解析 —— Flink-metrics-datadog
20、Flink Metrics 源码解析 —— Flink-metrics-dropwizard
21、Flink Metrics 源码解析 —— Flink-metrics-graphite
22、Flink Metrics 源码解析 —— Flink-metrics-influxdb
23、Flink Metrics 源码解析 —— Flink-metrics-jmx
24、Flink Metrics 源码解析 —— Flink-metrics-slf4j
25、Flink Metrics 源码解析 —— Flink-metrics-statsd
26、Flink Metrics 源码解析 —— Flink-metrics-prometheus

27、Flink 源码解析 —— 如何获取 ExecutionGraph ?


