
第五章 —— Table API & SQL
Flink 中除了 DataStream 和 DataSet API,还有比较高级的 Table API & SQL,它可以帮助我们简化开发的过程,能够快读的运用 Flink 去完成一些需求,本章将对 Flink Table API & SQL 进行讲解,并将与其他的 API 结合对比分析。
5.1 Flink Table & SQL 概念与通用 API
前面的内容都是讲解 DataStream 和 DataSet API 相关的,在 1.2.5 节中讲解 Flink API 时提及到 Flink 的高级 API —— Table API & SQL,本节将开始 Table & SQL 之旅。
5.1.1 新增 Blink SQL 查询处理器
在 Flink 1.9 版本中,合进了阿里巴巴开源的 Blink 版本中的大量代码,其中最重要的贡献就是 Blink SQL 了。在 Blink 捐献给 Apache Flink 之后,社区就致力于为 Table API & SQL 集成 Blink 的查询优化器和 runtime。先来看下 1.8 版本的 Flink Table 项目结构如下图所示。
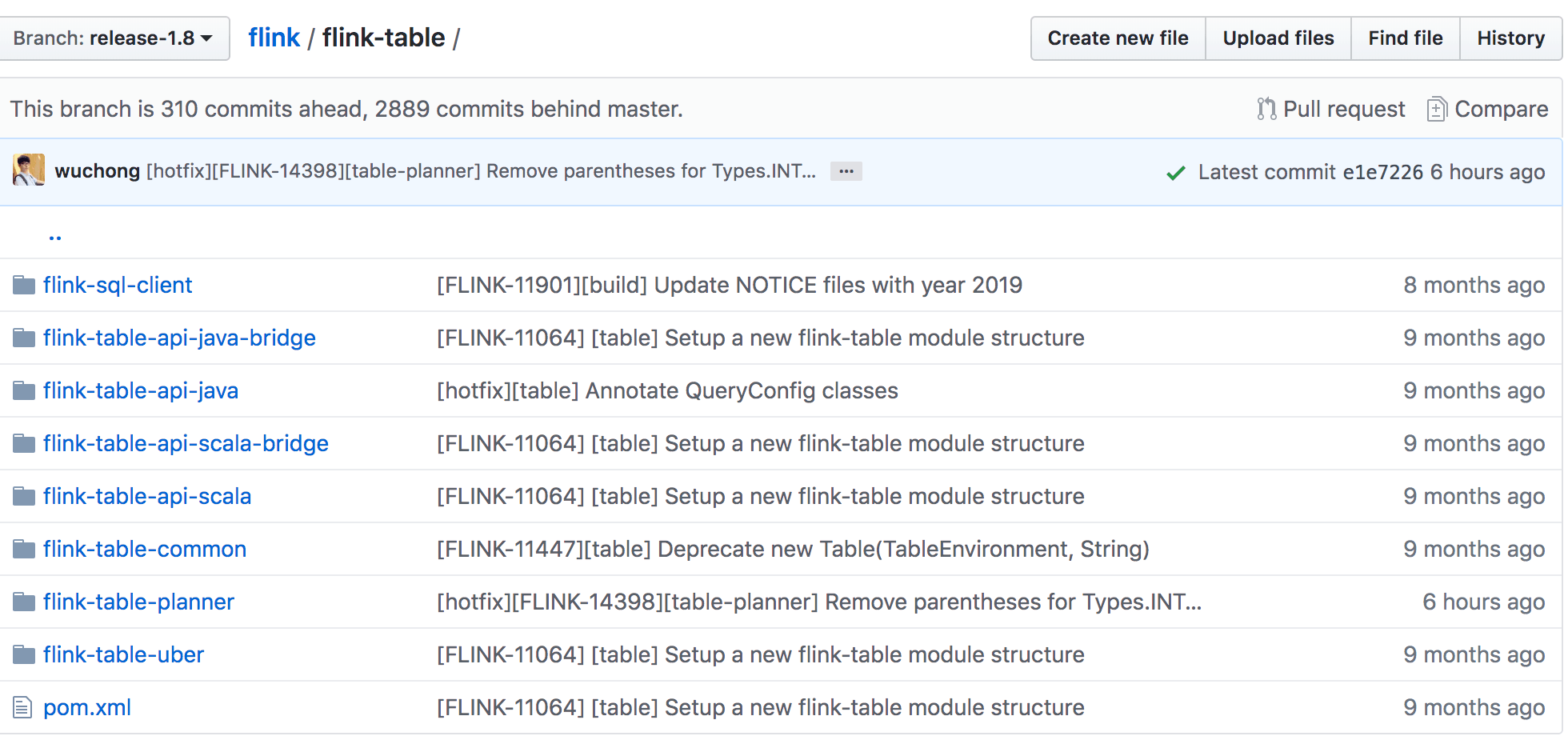
1.9 版本的 Flink Table 项目结构图如下图所示:
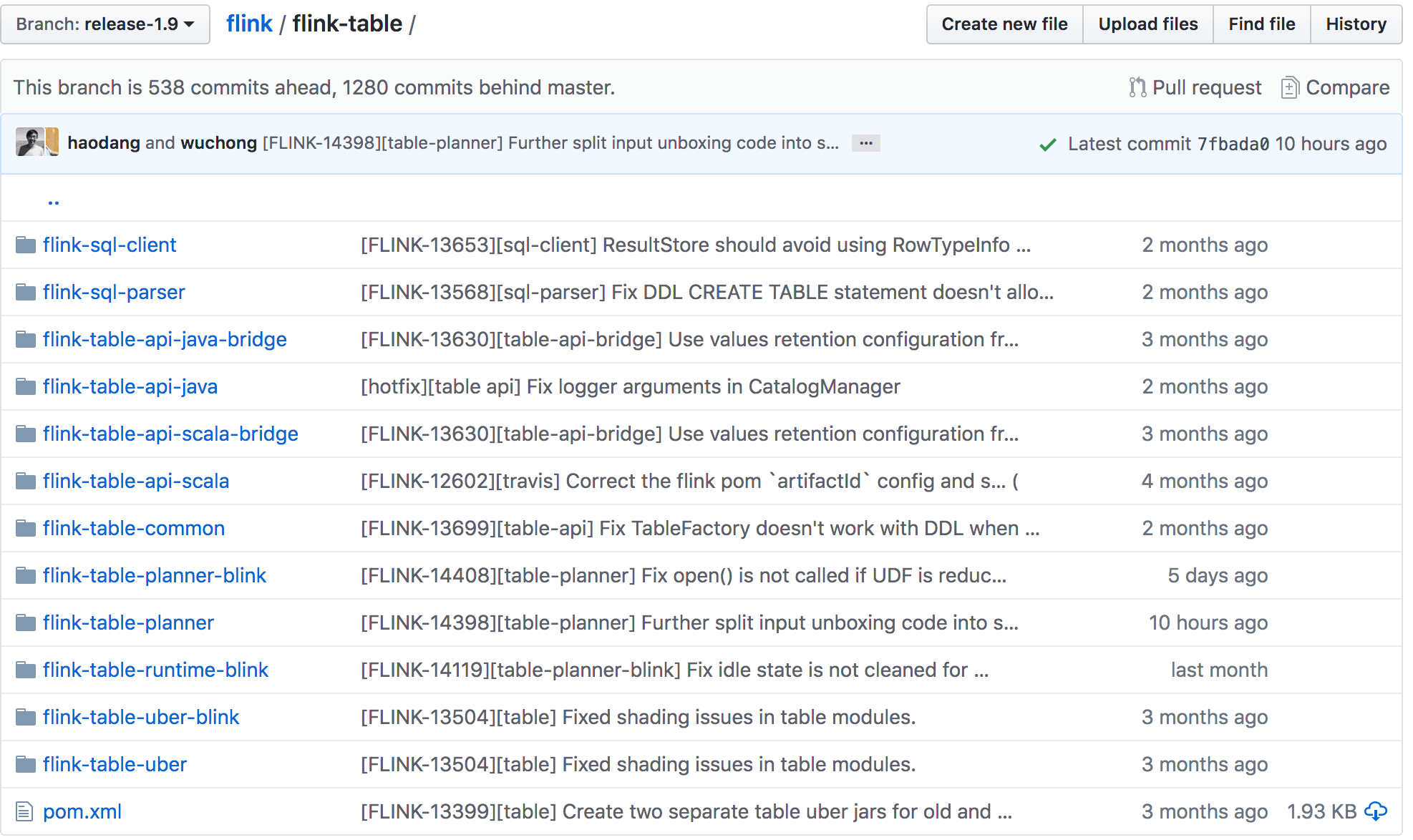
可以发现新增了 flink-sql-parser、flink-table-planner-blink、flink-table-runtime-blink、flink-table-uber-blink 模块,对 Flink Table 模块的重构详细内容可以参考 FLIP-32。这样对于 Java 和 Scala API 模块、优化器以及 runtime 模块来说,分层更清楚,接口更明确。
另外 flink-table-planner-blink 模块中实现了新的优化器接口,所以现在有两个插件化的查询处理器来执行 Table API & SQL:1.9 以前的 Flink 处理器和新的基于 Blink 的处理器。基于 Blink 的查询处理器提供了更好的 SQL 覆盖率、支持更广泛的查询优化、改进了代码生成机制、通过调优算子的实现来提升批处理查询的性能。除此之外,基于 Blink 的查询处理器还提供了更强大的流处理能力,包括了社区一些非常期待的新功能(如维表 Join、TopN、去重)和聚合场景缓解数据倾斜的优化,以及内置更多常用的函数,具体可以查看 flink-table-runtime-blink 代码。目前整个模块的结构如下图所示:
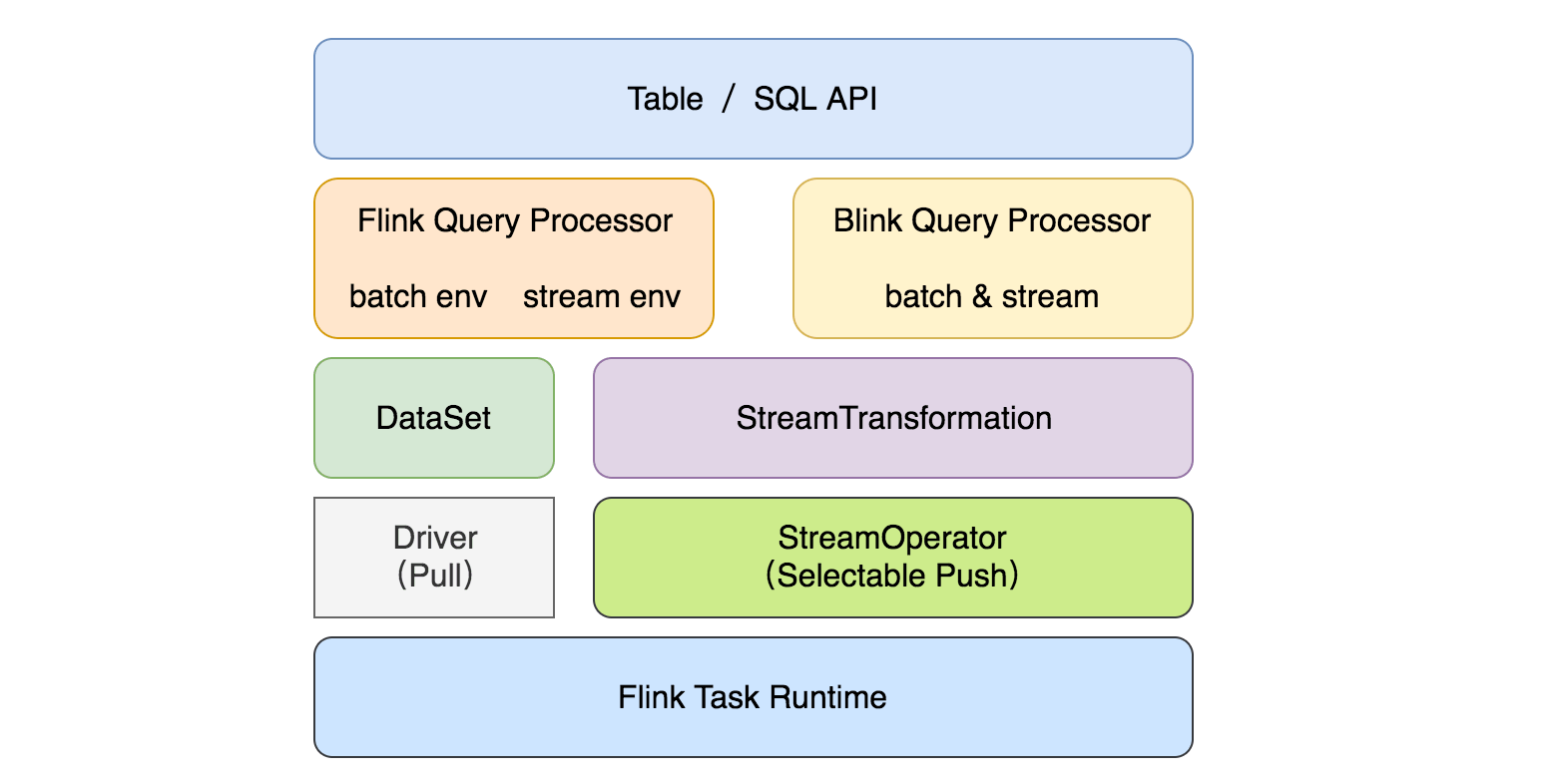
注意:两个查询处理器之间的语义和功能大部分是一致的,但未完全对齐,因为基于 Blink 的查询处理器还在优化中,所以在 1.9 版本中默认查询处理器还是 1.9 之前的版本。如果你想使用 Blink 处理器的话,可以在创建 TableEnvironment 时通过 EnvironmentSettings 配置启用。被选择的处理器必须要在正在执行的 Java 进程的类路径中。对于集群设置,默认两个查询处理器都会自动地加载到类路径中。如果要在 IDE 中运行一个查询,需要在项目中添加 planner 依赖。
5.1.2 为什么选择 Table API & SQL?
在 1.2 节中介绍了 Flink 的 API 是包含了 Table API & SQL,在 1.3 节中也介绍了在 Flink 1.9 中阿里开源的 Blink 分支中的很强大的 SQL 功能合并进 Flink 主分支,另外通过阿里 Blink 相关的介绍,可以知道阿里在 SQL 功能这块是做了很多的工作。从前面章节的内容可以发现 Flink 的 DataStream/DataSet API 的功能已经很全并且很强大了,常见复杂的数据处理问题也都可以处理,那么社区为啥还在一直推广 Table API & SQL 呢?
其实通过观察其它的大数据组件,就不会好奇了,比如 Spark、Storm、Beam、Hive 、KSQL(面向 Kafka 的 SQL 引擎)、Elasticsearch、Phoenix(使用 SQL 进行 HBase 数据的查询)等,可以发现 SQL 已经成为各个大数据组件必不可少的数据查询语言,那么 Flink 作为一个大数据实时处理引擎,笔者对其支持 SQL 查询流数据也不足为奇了,但是还是来稍微介绍一下 Table API & SQL。
Table API & SQL 是一种关系型 API,用户可以像操作数据库一样直接操作流数据,而不再需要通过 DataStream API 来写很多代码完成计算需求,更不用手动去调优你写的代码,另外 SQL 最大的优势在于它是一门学习成本很低的语言,普及率很高,用户基数大,和其他的编程语言相比,它的入门相对简单。
除了上面的原因,还有一个原因是:可以借助 Table API & SQL 统一流处理和批处理,因为在 DataStream/DataSet API 中,用户开发流作业和批作业需要去了解两种不同的 API,这对于公司有些开发能力不高的数据分析师来说,学习成本有点高,他们其实更擅长写 SQL 来分析。Table API & SQL 做到了批与流上的查询具有同样的语法语义,因此不用改代码就能同时在批和流上执行。
总结来说,为什么选择 Table API & SQL:
- 声明式语言表达业务逻辑
- 无需代码编程 —— 易于上手
- 查询能够被有效的优化
- 查询可以高效的执行
5.1.3 Flink Table 项目模块
在上文中提及到 Flink Table 在 1.8 和 1.9 的区别,这里还是要再讲解一下这几个依赖,因为只有了解清楚了之后,我们在后面开发的时候才能够清楚挑选哪种依赖。它有如下几个模块:
- flink-table-common:table 中的公共模块,可以用于通过自定义 function,format 等来扩展 Table 生态系统
- flink-table-api-java:支持使用 Java 语言,纯 Table&SQL API
- flink-table-api-scala:支持使用 Scala 语言,纯 Table&SQL API
- flink-table-api-java-bridge:支持使用 Java 语言,包含 DataStream/DataSet API 的 Table&SQL API(推荐使用)
- flink-table-api-scala-bridge:支持使用 Scala 语言,带有 DataStream/DataSet API 的 Table&SQL API(推荐使用)
- flink-sql-parser:SQL 语句解析层,主要依赖 calcite
- flink-table-planner:Table 程序的 planner 和 runtime
- flink-table-uber:将上诉模块打成一个 fat jar,在 lib 目录下
- flink-table-planner-blink:Blink 的 Table 程序的 planner(阿里开源的版本)
- flink-table-runtime-blink:Blink 的 Table 程序的 runtime(阿里开源的版本)
- flink-table-uber-blink:将 Blink 版本的 planner 和 runtime 与前面模块(除 flink-table-planner 模块)打成一个 fat jar,在 lib 目录下,如下图所示。
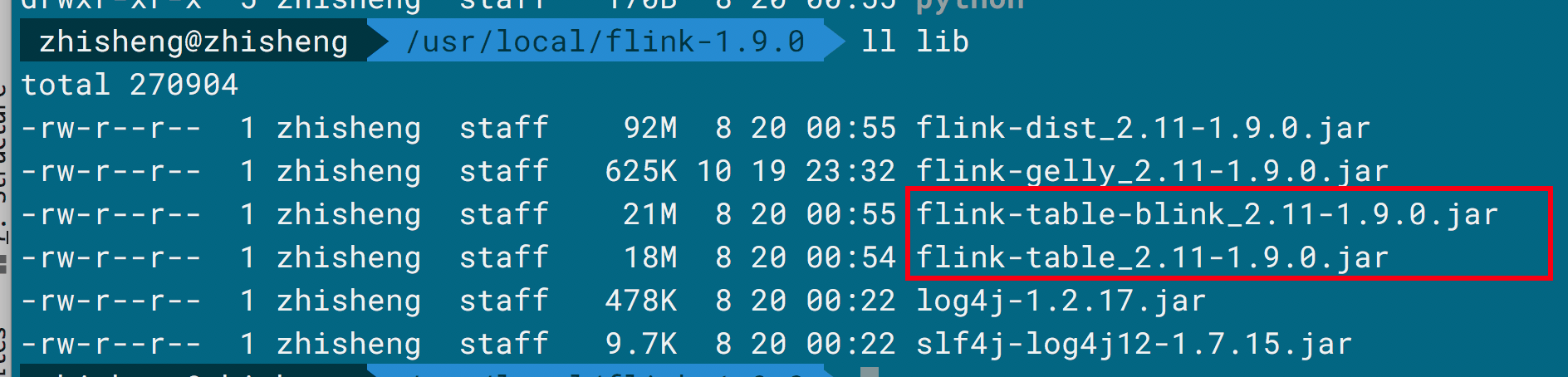
- flink-sql-client:SQL 客户端
5.1.4 两种 planner 之间的区别
上面讲了两种不同的 planner 之间包含的模块有点区别,但是具体有什么区别如下所示:
- Blink planner 将批处理作业视为流的一种特殊情况。因此不支持 Table 和 DataSet 之间的转换,批处理作业会转换成 DataStream 程序,而不会转换成 DataSet 程序,流作业还是转换成 DataStream 程序。
- Blink planner 不支持 BatchTableSource,而是使用有界的(bounded) StreamTableSource 代替它。
- Blink planner 仅支持全新的 Catalog,不支持已经废弃的 ExternalCatalog。
- 以前的 planner 中 FilterableTableSource 的实现与现在的 Blink planner 有冲突,在以前的 planner 中是叠加 PlannerExpressions(在未来的版本中会移除),而在 Blink planner 中是 Expressions。
- 基于字符串的 KV 键值配置选项仅可以在 Blink planner 中使用。
- PlannerConfig 的实现(CalciteConfig)在两种 planner 中不同。
- Blink planner 会将多个 sink 优化在同一个 DAG 中(只在 TableEnvironment 中支持,StreamTableEnvironment 中不支持),而以前的 planner 是每个 sink 都有一个 DAG 中,相互独立的。
- 以前的 planner 不支持 catalog 统计,而 Blink planner 支持。
在了解到了两种 planner 的区别后,接下来开始 Flink Table API & SQL 之旅。
5.1.5 添加项目依赖
因为在 Flink 1.9 版本中有两个 planner,所以得根据你使用的 planner 来选择对应的依赖,假设你选择的是最新的 Blink 版本,那么添加下面的依赖:
1 | <dependency> |
如果是以前的 planner,则使用下面这个依赖:
1 | <dependency> |
如果要自定义 format 格式或者自定义 function,则需要添加 flink-table-common 依赖:
1 | <dependency> |
5.1.6 创建一个 TableEnvironment
TableEnvironment 是 Table API 和 SQL 的统称,它负责的内容有:
- 在内部的 catalog 注册 Table
- 注册一个外部的 catalog
- 执行 SQL 查询
- 注册用户自定义的 function
- 将 DataStream 或者 DataSet 转换成 Table
- 保持对 ExecutionEnvironment 和 StreamExecutionEnvironment 的引用
Table 总是会绑定在一个指定的 TableEnvironment,不能在同一个查询中组合不同 TableEnvironment 的 Table,比如 join 或 union 操作。你可以使用下面的几种静态方法创建 TableEnvironment。
1 | //创建 StreamTableEnvironment |
你需要根据你的程序来使用对应的 TableEnvironment,是 BatchTableEnvironment 还是 StreamTableEnvironment。默认两个 planner 都是在 Flink 的安装目录下 lib 文件夹中存在的,所以应该在你的程序中指定使用哪种 planner。
1 | // Flink Streaming query |
如果在 lib 目录下只存在一个 planner,则可以使用 useAnyPlanner 来创建指定的 EnvironmentSettings。
5.1.7 Table API & SQL 应用程序的结构
批处理和流处理的 Table API & SQL 作业都有相同的模式,它们的代码结构如下:
1 | //根据前面内容创建一个 TableEnvironment,指定是批作业还是流作业 |
5.1.8 Catalog 中注册 Table
Table 有两种类型,输入表和输出表,可以在 Table API & SQL 查询中引用输入表并提供输入数据,输出表可以用于将 Table API & SQL 的查询结果发送到外部系统。输出表可以通过 TableSink 来注册,输入表可以从各种数据源进行注册:
- 已经存在的 Table 对象,通过是 Table API 或 SQL 查询的结果
- 连接了外部系统的 TableSource,比如文件、数据库、MQ
- 从 DataStream 或 DataSet 程序中返回的 DataStream 和 DataSet
注册 Table
在 TableEnvironment 中可以像下面这样注册一个 Table:
1 | //创建一个 TableEnvironment |
注册 TableSource
注册 TableSink
5.1.9 注册外部的 Catalog
5.1.10 查询 Table
Table API
SQL
Table API & SQL
5.1.11 提交 Table
5.1.12 翻译并执行查询
加入知识星球可以看到上面文章:https://t.zsxq.com/MNBEYvf

5.1.13 小结与反思
本节介绍了 Flink 新的 planner,然后详细的和之前的 planner 做了对比,然后对 Table API & SQL 中的概念做了介绍,还通过样例去介绍了它们的通用 API。


