
4.2 Flink 状态后端存储
在 4.1 节中介绍了 Flink 中的状态,那么在生产环境中,随着作业的运行时间变长,状态会变得越来越大,那么如何将这些状态存储也是 Flink 要解决的一大难点,本节来讲解下 Flink 中不同类型的状态后端存储。
4.2.1 State Backends
当需要对具体的某一种 State 做 Checkpoint 时,此时就需要具体的状态后端存储,刚好 Flink 内置提供了不同的状态后端存储,用于指定状态的存储方式和位置。状态可以存储在 Java 堆内存中或者堆外,在 Flink 安装路径下 conf 目录中的 flink-conf.yaml 配置文件中也有状态后端存储相关的配置,为此在 Flink 源码中还特有一个 CheckpointingOptions 类来控制 state 存储的相关配置,该类中有如下配置:
- state.backend: 用于存储和进行状态 Checkpoint 的状态后端存储方式,无默认值
- state.checkpoints.num-retained: 要保留的已完成 Checkpoint 的最大数量,默认值为 1
- state.backend.async: 状态后端是否使用异步快照方法,默认值为 true
- state.backend.incremental: 状态后端是否创建增量检查点,默认值为 false
- state.backend.local-recovery: 状态后端配置本地恢复,默认情况下,本地恢复被禁用
- taskmanager.state.local.root-dirs: 定义存储本地恢复的基于文件的状态的目录
- state.savepoints.dir: 存储 savepoints 的目录
- state.checkpoints.dir: 存储 Checkpoint 的数据文件和元数据
- state.backend.fs.memory-threshold: 状态数据文件的最小大小,默认值是 1024
虽然配置这么多,但是,Flink 还支持基于每个 Job 单独设置状态后端存储,方法如下:
1 | StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); |
StateBackend 接口的三种实现类如下图所示:
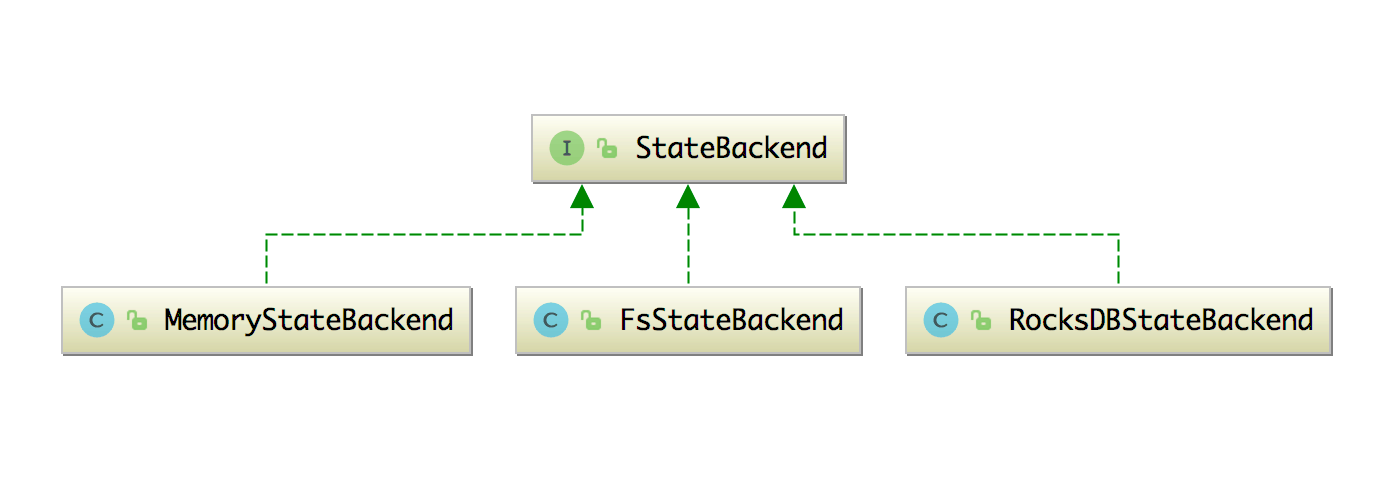
上面三种方式取一种就好了。但是有三种方式,我们该如何去挑选用哪种去存储状态呢?下面讲讲这三种的特点以及该如何选择。
4.2.2 MemoryStateBackend 的用法及分析
如果 Job 没有配置指定状态后端存储的话,就会默认采取 MemoryStateBackend 策略。如果你细心的话,可以从你的 Job 中看到类似日志如下:
1 | 2019-04-28 00:16:41.892 [Sink: zhisheng (1/4)] INFO org.apache.flink.streaming.runtime.tasks.StreamTask - No state backend has been configured, using default (Memory / JobManager) MemoryStateBackend (data in heap memory / checkpoints to JobManager) (checkpoints: 'null', savepoints: 'null', asynchronous: TRUE, maxStateSize: 5242880) |
上面日志的意思就是说如果没有配置任何状态存储,使用默认的 MemoryStateBackend 策略,这种状态后端存储把数据以内部对象的形式保存在 TaskManagers 的内存(JVM 堆)中,当应用程序触发 Checkpoint 时,会将此时的状态进行快照然后存储在 JobManager 的内存中。因为状态是存储在内存中的,所以这种情况会有点限制,比如:
- 不太适合在生产环境中使用,仅用于本地测试的情况较多,主要适用于状态很小的 Job,因为它会将状态最终存储在 JobManager 中,如果状态较大的话,那么会使得 JobManager 的内存比较紧张,从而导致 JobManager 会出现 OOM 等问题,然后造成连锁反应使所有的 Job 都挂掉,所以 Job 的状态与之前的 Checkpoint 的数据所占的内存要小于 JobManager 的内存。
- 每个单独的状态大小不能超过最大的 DEFAULT_MAX_STATE_SIZE(5MB),可以通过构造 MemoryStateBackend 参数传入不同大小的 maxStateSize。
- Job 的操作符状态和 keyed 状态加起来都不要超过 RPC 系统的默认配置 10 MB,虽然可以修改该配置,但是不建议去修改。
另外就是 MemoryStateBackend 支持配置是否是异步快照还是同步快照,它有一个字段 asynchronousSnapshots 来表示,可选值有:
- TRUE(表示使用异步的快照,这样可以避免因快照而导致数据流处理出现阻塞等问题)
- FALSE(同步)
- UNDEFINED(默认值)
在构造 MemoryStateBackend 的默认函数时是使用的 UNDEFINED,而不是异步:
1 | public MemoryStateBackend() { |
网上有人说默认是异步的,这里给大家解释清楚一下,从上面的那条日志打印的确实也是表示异步,但是前提是你对 State 无任何操作,笔者跟了下源码,当你没有配置任何的 state 时,它是会在 StateBackendLoader 类中通过 MemoryStateBackendFactory 来创建的 state 的,如下图所示。
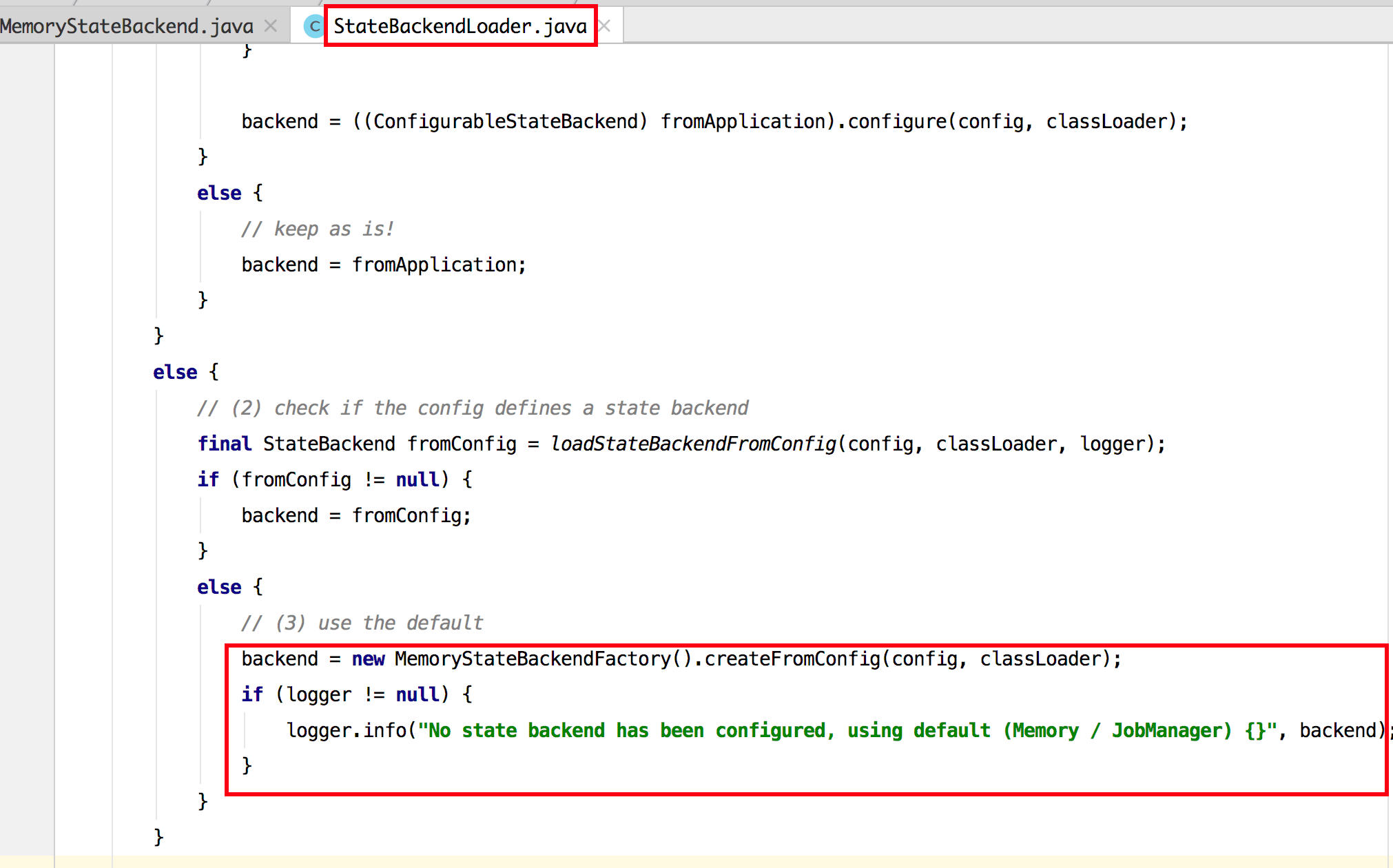
继续跟进 MemoryStateBackendFactory 可以发现他这里创建了一个 MemoryStateBackend 实例并通过 configure 方法进行配置,大概流程代码是:
1 | //MemoryStateBackendFactory 类 |
可以发现最终是通过读取 state.backend.async 参数的默认值(true)来配置是否要异步的进行快照,但是如果你手动配置 MemoryStateBackend 的话,利用无参数的构造方法,那么就不是默认异步,如果想使用异步的话,需要利用下面这个构造函数(需要传入一个 boolean 值,true 代表异步,false 代表同步):
1 | public MemoryStateBackend(boolean asynchronousSnapshots) { |
如果你再细看了这个 MemoryStateBackend 类的话,那么你可能会发现这个构造函数:
1 | public MemoryStateBackend(@Nullable String checkpointPath, @Nullable String savepointPath) { |
这个也是用来创建一个 MemoryStateBackend 的,它需要传入的参数是两个路径(checkpointPath、savepointPath),其中 checkpointPath 是写入 Checkpoint 元数据的路径,savepointPath 是写入 savepoint 的路径。
这个来看看 MemoryStateBackend 的继承关系图可以更明确的知道它是继承自 AbstractFileStateBackend,然后 AbstractFileStateBackend 这个抽象类就是为了能够将状态存储中的数据或者元数据进行文件存储的,如下图所示。
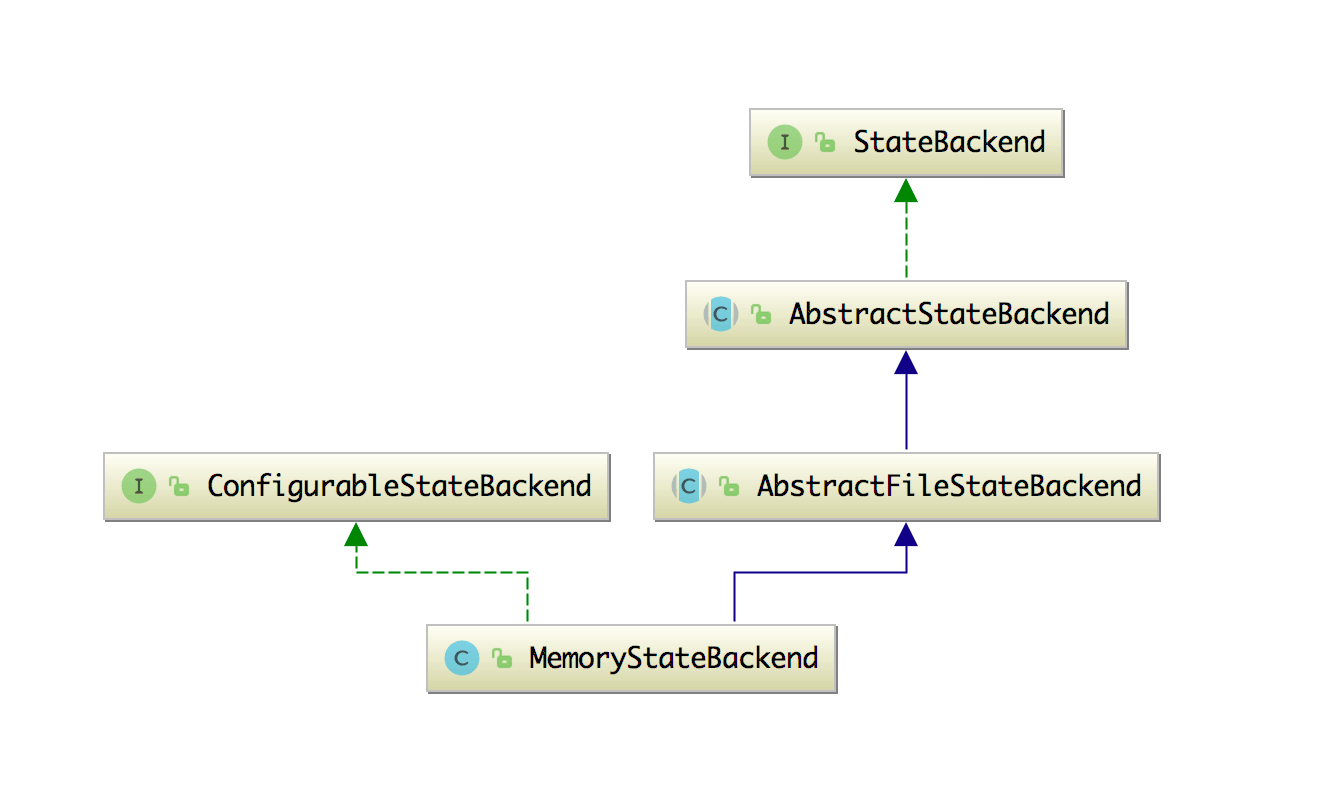
所以 FsStateBackend 和 MemoryStateBackend 都会继承该类。
4.2.3 FsStateBackend 的用法及分析
这种状态后端存储也是将工作状态存储在 TaskManager 中的内存(JVM 堆)中,但是 Checkpoint 的时候,它和 MemoryStateBackend 不一样,它是将状态存储在文件(可以是本地文件,也可以是 HDFS)中,这个文件具体是哪种需要配置,比如:”hdfs://namenode:40010/flink/checkpoints” 或 “file://flink/checkpoints” (通常使用 HDFS 比较多,如果是使用本地文件,可能会造成 Job 恢复的时候找不到之前的 checkkpoint,因为 Job 重启后如果由调度器重新分配在不同的机器的 TaskManager 执行时就会导致这个问题,所以还是建议使用 HDFS 或者其他的分布式文件系统)。
同样 FsStateBackend 也是支持通过 asynchronousSnapshots 字段来控制是使用异步还是同步来进行 Checkpoint 的,异步可以避免在状态 Checkpoint 时阻塞数据流的处理,然后还有一点的就是在 FsStateBackend 有个参数 fileStateThreshold,如果状态大小比 MAX_FILE_STATE_THRESHOLD(1MB) 小的话,那么会将状态数据直接存储在 meta data 文件中,而不是存储在配置的文件中(避免出现很小的状态文件),如果该值为 “-1” 表示尚未配置,在这种情况下会使用默认值(1024,该默认值可以通过 state.backend.fs.memory-threshold 来配置)。
那么我们该什么时候使用 FsStateBackend 呢?
- 如果你要处理大状态,长窗口等有状态的任务,那么 FsStateBackend 就比较适合
- 使用分布式文件系统,如 HDFS 等,这样 failover 时 Job 的状态可以恢复
使用 FsStateBackend 需要注意的地方有什么呢?
- 工作状态仍然是存储在 TaskManager 中的内存中,虽然在 Checkpoint 的时候会存在文件中,所以还是得注意这个状态要保证不超过 TaskManager 的内存
4.2.4 RocksDBStateBackend 的用法及分析
4.2.5 如何选择状态后端存储?
4.2.6 小结与反思
加入知识星球可以看到上面文章: https://t.zsxq.com/RNJeqFy



