
8.2 搭建一套 Flink 监控系统
8.1 节中讲解了 JobManager、TaskManager 和 Flink Job 的监控,以及需要关注的监控指标有哪些。本节带大家讲解一下如何搭建一套完整的 Flink 监控系统,如果你所在的公司没有专门的监控平台,那么可以根据本节的内容来为公司搭建一套属于自己公司的 Flink 监控系统。
8.2.1 利用 API 获取监控数据
熟悉 Flink 的朋友都知道 Flink 的 UI 上面已经详细地展示了很多监控指标的数据,并且这些指标还是比较重要的,所以如果不想搭建额外的监控系统,那么直接利用 Flink 自身的 UI 就可以获取到很多重要的监控信息。这里要讲的是这些监控信息其实也是通过 Flink 自身的 Rest API 来获取数据的,所以其实要搭建一个粗糙的监控平台,也是可以直接利用现有的接口定时去获取数据,然后将这些指标的数据存储在某种时序数据库中,最后用些可视化图表做个展示,这样一个完整的监控系统就做出来了。
这里通过 Chrome 浏览器的控制台来查看一下有哪些 REST API 是用来提供监控数据的。
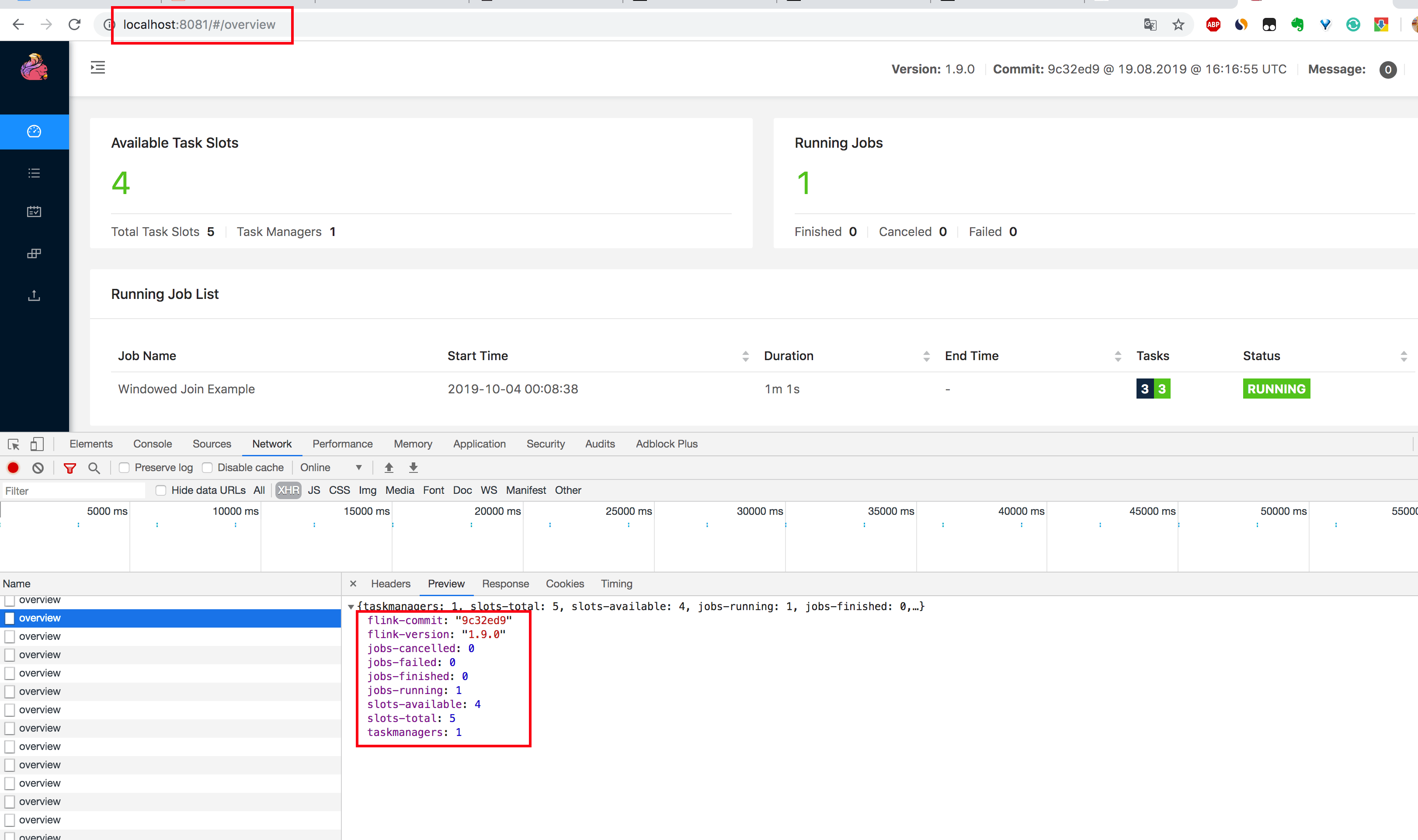
1.在 Chrome 浏览器中打开 http://localhost:8081/overview 页面,可以获取到整个 Flink 集群的资源信息:TaskManager 个数(TaskManagers)、Slot 总个数(Total Task Slots)、可用 Slot 个数(Available Task Slots)、Job 运行个数(Running Jobs)、Job 运行状态(Finished 0 Canceled 0 Failed 0)等,如下图所示。
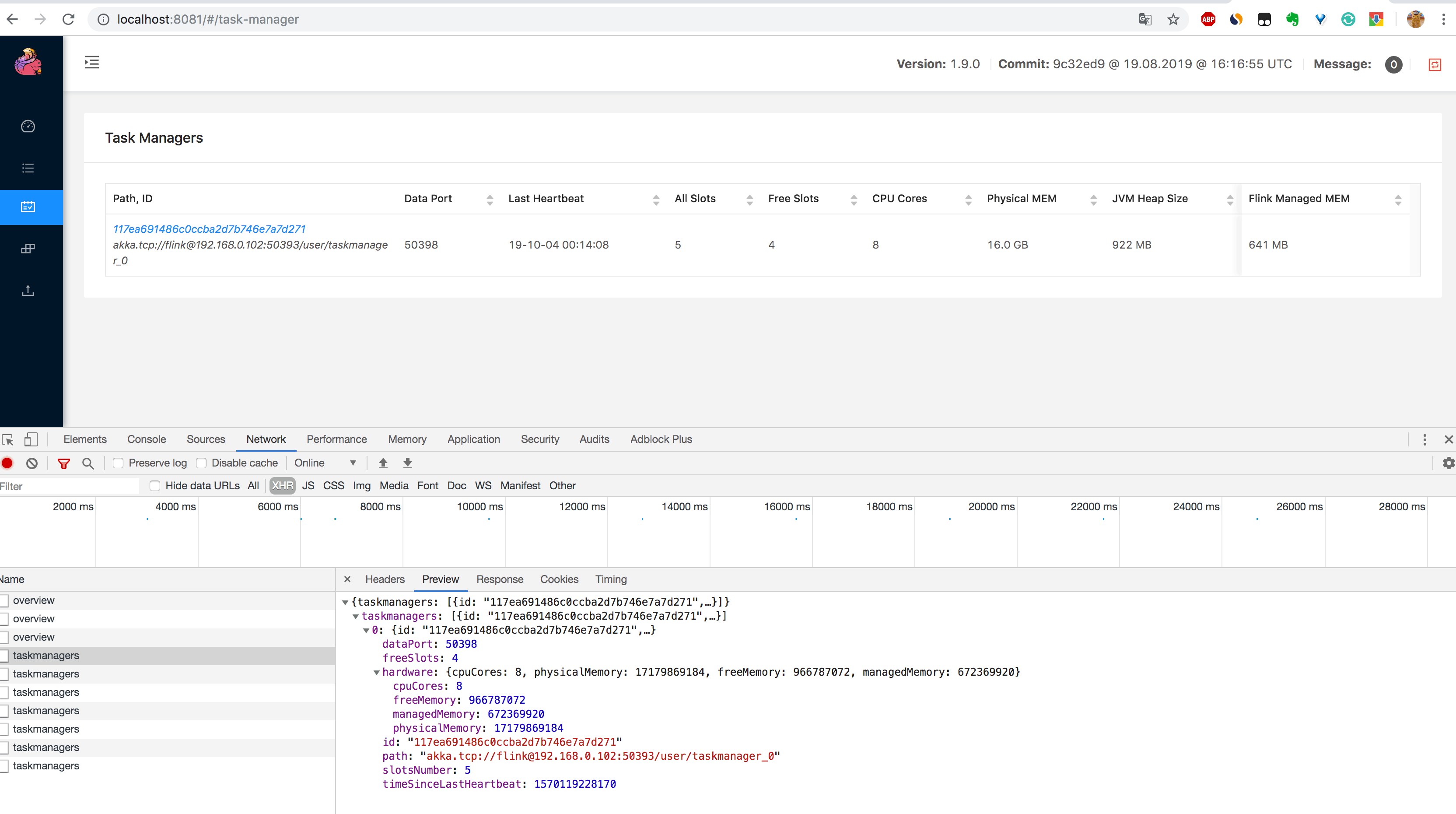
2.通过 http://localhost:8081/taskmanagers 页面查看 TaskManager 列表,可以知道该集群下所有 TaskManager 的信息(数据端口号(Data Port)、上一次心跳时间(Last Heartbeat)、总共的 Slot 个数(All Slots)、空闲的 Slot 个数(Free Slots)、以及 CPU 和内存的分配使用情况,如下图所示。
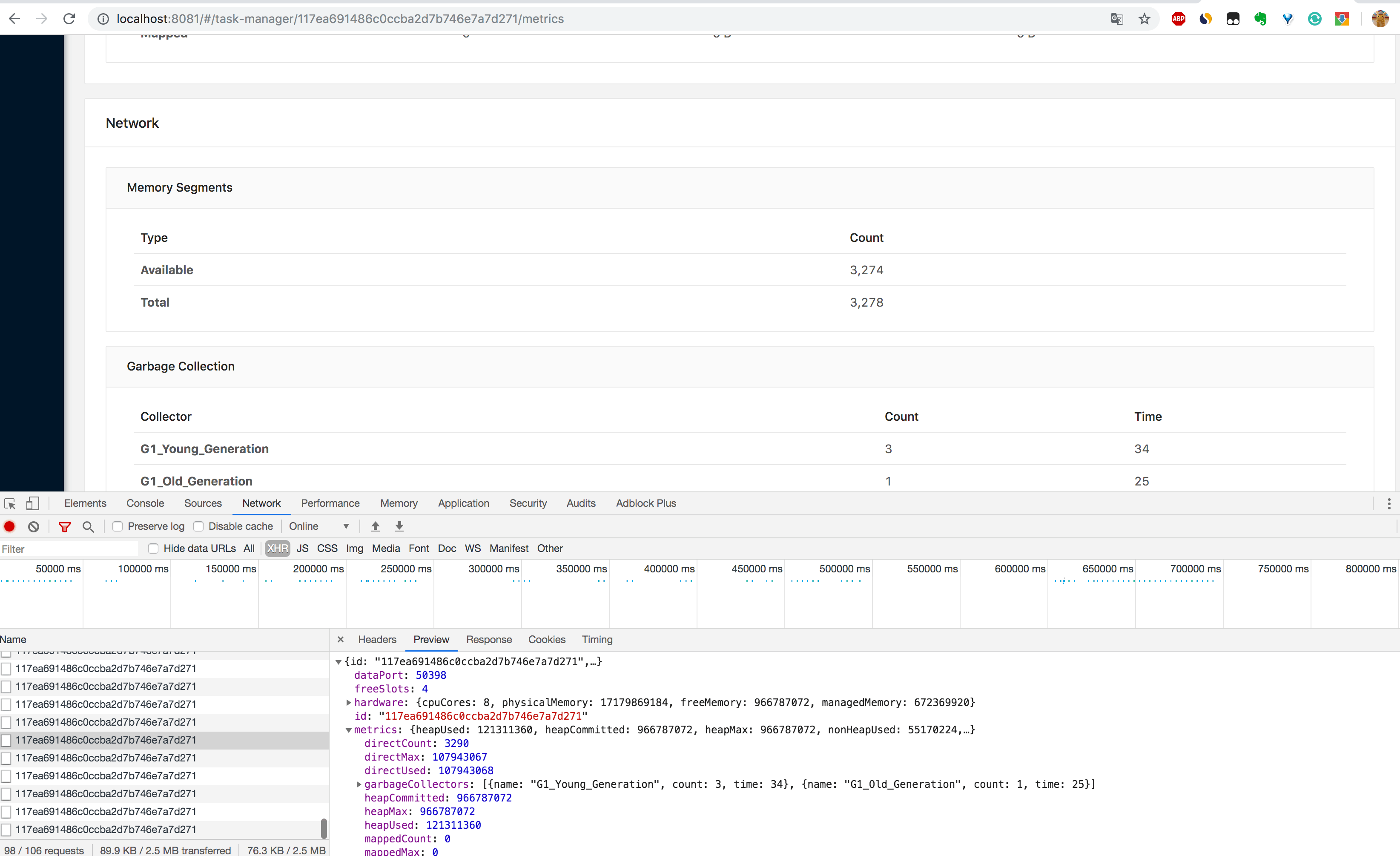
3.通过 http://localhost:8081/taskmanagers/tm_id 页面查看 TaskManager 的具体情况(这里的 tm_id 是个随机的 UUID 值)。在这个页面上,除了上一条的监控信息可以查看,还可以查看该 TaskManager 的 JVM(堆和非堆)、Direct 内存、网络、GC 次数和时间,如下图所示。内存和 GC 这些信息非常重要,很多时候 TaskManager 频繁重启的原因就是 JVM 内存设置得不合理,导致频繁的 GC,最后使得 OOM 崩溃,不得不重启。
另外如果你在 /taskmanagers/tm_id 接口后面加个 /log 就可以查看该 TaskManager 的日志,注意,在 Flink 中的日志和平常自己写的应用中的日志是不一样的。在 Flink 中,日志是以 TaskManager 为概念打印出来的,而不是以单个 Job 打印出来的,如果你的 Job 在多个 TaskManager 上运行,那么日志就会在多个 TaskManager 中打印出来。如果一个 TaskManager 中运行了多个 Job,那么它里面的日志就会很混乱,查看日志时会发现它为什么既有这个 Job 打出来的日志,又有那个 Job 打出来的日志,如果你之前有这个疑问,那么相信你看完这里,就不会有疑问了。
对于这种设计是否真的好,不同的人有不同的看法,在 Flink 的 Issue 中就有人提出了该问题,Issue 中的描述是希望日志可以是 Job 与 Job 之间的隔离,这样日志更方便采集和查看,对于排查问题也会更快。对此国内有公司也对这一部分做了改进,不知道正在看本书的你是否有什么好的想法可以解决 Flink 的这一痛点。
4.通过 http://localhost:8081/#/job-manager/config 页面可以看到可 JobManager 的配置信息,另外通过 http://localhost:8081/jobmanager/log 页面可以查看 JobManager 的日志详情。
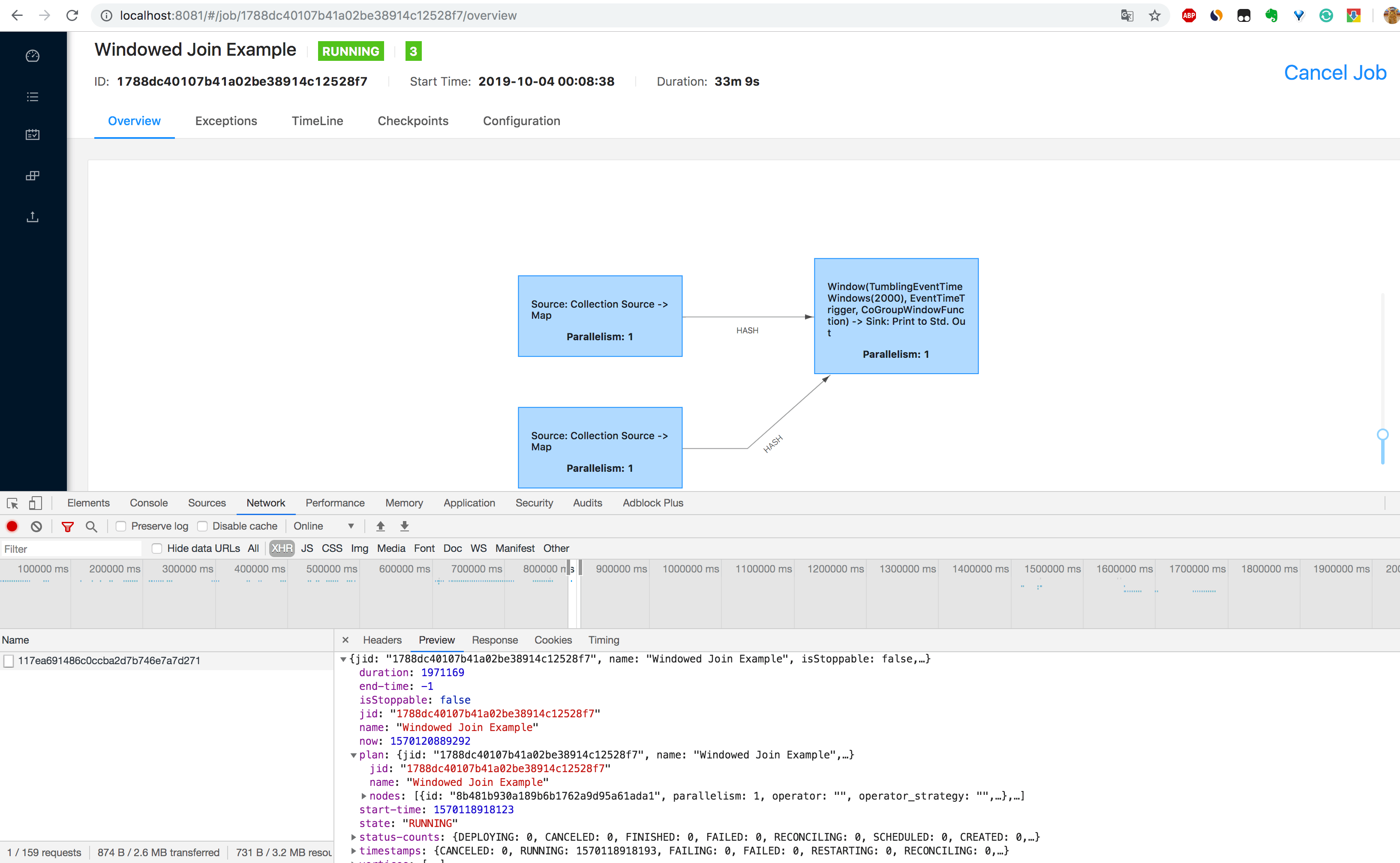
5.通过 http://localhost:8081/jobs/job_id 页面可以查看 Job 的监控数据,如下图所示,由于指标(包括了 Job 的 Task 数据、Operator 数据、Exception 数据、Checkpoint 数据等)过多,大家可以自己在本地测试查看。
上面列举了几个 REST API(不是全部),主要是为了告诉大家,其实这些接口我们都知道,那么我们也可以利用这些接口去获取对应的监控数据,然后绘制出更酷炫的图表,用更直观的页面将这些数据展示出来,这样就能更好地控制。
除了利用 Flink UI 提供的接口去定时获取到监控数据,其实 Flink 还提供了很多的 reporter 去上报监控数据,比如 JMXReporter、PrometheusReporter、PrometheusPushGatewayReporter、InfluxDBReporter、StatsDReporter 等,这样就可以根据需求去定制获取到 Flink 的监控数据,下面教大家使用几个常用的 reporter。
相关 Rest API 可以查看官网链接:rest-api-integration
8.2.2 Metrics 类型简介
可以在继承自 RichFunction 的函数中通过 getRuntimeContext().getMetricGroup() 获取 Metric 信息,常见的 Metrics 的类型有 Counter、Gauge、Histogram、Meter。
Counter
Gauge
Histogram
Meter
8.2.3 利用 JMXReporter 获取监控数据
8.2.4 利用 PrometheusReporter 获取监控数据
8.2.5 利用 PrometheusPushGatewayReporter 获取监控数据
8.2.6 利用 InfluxDBReporter 获取监控数据
8.2.7 安装 InfluxDB 和 Grafana
安装 InfluxDB
安装 Grafana
8.2.8 配置 Grafana 展示监控数据
加入知识星球可以看到上面文章:https://t.zsxq.com/f66iAMz

8.2.9 小结与反思
本节讲了如何利用 API 去获取监控数据,对 Metrics 的类型进行介绍,然后还介绍了怎么利用 Reporter 去将 Metrics 数据进行上报,并通过 InfluxDB + Grafana 搭建了一套 Flink 的监控系统。另外你还可以根据公司的需要使用其他的存储方案来存储监控数据,Grafana 也支持不同的数据源,你们公司的监控系统架构是怎么样的,是否可以直接接入这套监控系统?
作业部署上线后的监控尤其重要,虽说 Flink UI 自身提供了不少的监控信息,但是个人觉得还是比较弱,还是得去搭建一套完整的监控系统去监控 Flink 中的 JobManager、TaskManager 和作业。本章中讲解了 Flink UI 上获取监控数据的方式,还讲解了如何利用 Flink 自带的 Metrics Reporter 去采集各种监控数据,从而利用时序数据库存储这些监控数据,最后用 Grafana 这种可视化比较好的去展示这些监控数据,从而达到作业真正的监控运维效果。
整套监控系统也希望你可以运用在你们公司,当然你不一定非得选用相同的存储时序数据库,这样可以为你们节省不少作业出问题后的排查时间。


