
6.5 Flink 扩展库——Gelly
在 1.9 版本中还剩最后一个扩展库就是 Gelly,本节将带你了解一下 Gelly 的功能以及如何使用。
6.5.1 Gelly 简介
Gelly 是 Flink 的图 API 库,它包含了一组旨在简化 Flink 中图形分析应用程序开发的方法和实用程序。在 Gelly 中,可以使用类似于批处理 API 提供的高级函数来转换和修改图。Gelly 提供了创建、转换和修改图的方法以及图算法库。
6.5.2 使用 Gelly
因为 Gelly 是 Flink 项目中库的一部分,它本身不在 Flink 的二进制包中,所以运行 Gelly 项目(Java 应用程序)是需要将 opt/flink-gelly_2.11-1.9.0.jar 移动到 lib 目录中,如果是 Scala 应用程序则需要将 opt/flink-gelly-scala_2.11-1.9.0.jar 移动到 lib 中,接着运行下面的命令就可以运行一个 flink-gelly-examples 项目。
1 | ./bin/flink run examples/gelly/flink-gelly-examples_2.11-1.9.0.jar \ |
接下来可以在 UI 上看到运行的结果如下图所示:

如果是自己创建的 Gelly Java 应用程序,则需要添加如下依赖:
1 | <dependency> |
如果是 Gelly Scala 应用程序,添加下面的依赖:
1 | <dependency> |
6.5.3 Gelly API
引入好依赖后,接着将介绍一下 Gelly 该如何使用。
Graph 介绍
在 Gelly 中,一个图(Graph)由顶点的数据集(DataSet)和边的数据集(DataSet)组成。图中的顶点由 Vertex 类型来表示,一个 Vertex 由唯一的 ID 和一个值来表示。其中 Vertex 的 ID 必须是全局唯一的值,且实现了 Comparable 接口。如果节点不需要由任何值,则该值类型可以声明成 NullValue 类型。
1 | //创建一个 Vertex<Long,String> |
Graph 中的边由 Edge 类型来表示,一个 Edge 通常由源顶点的 ID,目标顶点的 ID 以及一个可选的值来表示。其中源顶点和目标顶点的类型必须与 Vertex 的 ID 类型相同。同样的,如果边不需要由任何值,则该值类型可以声明成 NullValue 类型。
1 | Edge<Long, Double> e = new Edge<Long, Double>(1L, 2L, 0.5); |
在 Gelly 中,一个 Edge 总是从源顶点指向目标顶点。如果图中每条边都能匹配一个从目标顶点到源顶点的 Edge,那么这个图可能是个无向图。同样地,无向图可以用这个方式来表示。
创建 Graph
可以通过以下几种方式创建一个 Graph:
- 从一个 Edge 数据集合和一个 Vertex 数据集合中创建图。
1 | ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment(); |
- 从一个表示边的 Tuple2 数据集合中创建图。Gelly 会将每个 Tuple2 转换成一个 Edge,其中第一个元素表示源顶点的 ID,第二个元素表示目标顶点的 ID,图中的顶点和边的 value 值均被设置为 NullValue。
1 | ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment(); |
- 从一个 Tuple3 数据集和一个可选的 Tuple2 数据集中生成图。在这种情况下,Gelly 会将每个 Tuple3 转换成 Edge,其中第一个元素域是源顶点 ID,第二个域是目标顶点 ID,第三个域是边的值。同样的,每个 Tuple2 会转换成一个顶点 Vertex,其中第一个域是顶点的 ID,第二个域是顶点的 value。
1 | ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment(); |
- 从一个表示边数据的CSV文件和一个可选的表示节点的CSV文件中生成图。在这种情况下,Gelly会将表示边的CSV文件中的每一行转换成一个Edge,其中第一个域表示源顶点ID,第二个域表示目标顶点ID,第三个域表示边的值。同样的,表示节点的CSV中的每一行都被转换成一个Vertex,其中第一个域表示顶点的ID,第二个域表示顶点的值。为了通过GraphCsvReader生成图,需要指定每个域的类型,可以使用 types、edgeTypes、vertexTypes、keyType 中的方法。
1 | //创建一个具有字符串 Vertex id、Long Vertex 和双边缘的图 |
- 从一个边的集合和一个可选的顶点的集合中生成图。如果在图创建的时候顶点的集合没有传入,Gelly 会依据数据的边数据集合自动地生成一个 Vertex 集合。这种情况下,创建的节点是没有值的。或者也可以像下面一样,在创建图的时候提供一个 MapFunction 方法来初始化节点的值。
1 | List<Vertex<Long, Long>> vertexList = new ArrayList... |
Graph 属性
Gelly 提供了下列方法来查询图的属性和指标:
1 | DataSet<Vertex<K, VV>> getVertices() |
Graph 转换
Graph 转换方式有下面几种方式:
- Map:Gelly 提供了专门的用于转换顶点值和边值的方法。mapVertices 和 mapEdges 会返回一个新图,图中的每个顶点和边的 ID 不会改变,但是顶点和边的值会根据用户自定义的映射方法进行修改。这些映射方法同时也可以修改顶点和边的值的类型。
- Translate:Gelly 还提供了专门用于根据用户定义的函数转换顶点和边的 ID 和值的值及类型的方法(translateGraphIDs/translateVertexValues/translateEdgeValues),是Map 功能的升级版,因为 Map 操作不支持修订顶点和边的 ID。
- Filter:Gelly 支持在图中的顶点上或边上执行一个用户指定的 filter 转换。filterOnEdges 会根据提供的在边上的断言在原图的基础上生成一个新的子图,注意,顶点的数据不会被修改。同样的 filterOnVertices 在原图的顶点上进行 filter 转换,不满足断言条件的源节点或目标节点会在新的子图中移除。该子图方法支持同时对顶点和边应用 filter 函数,如下图所示。
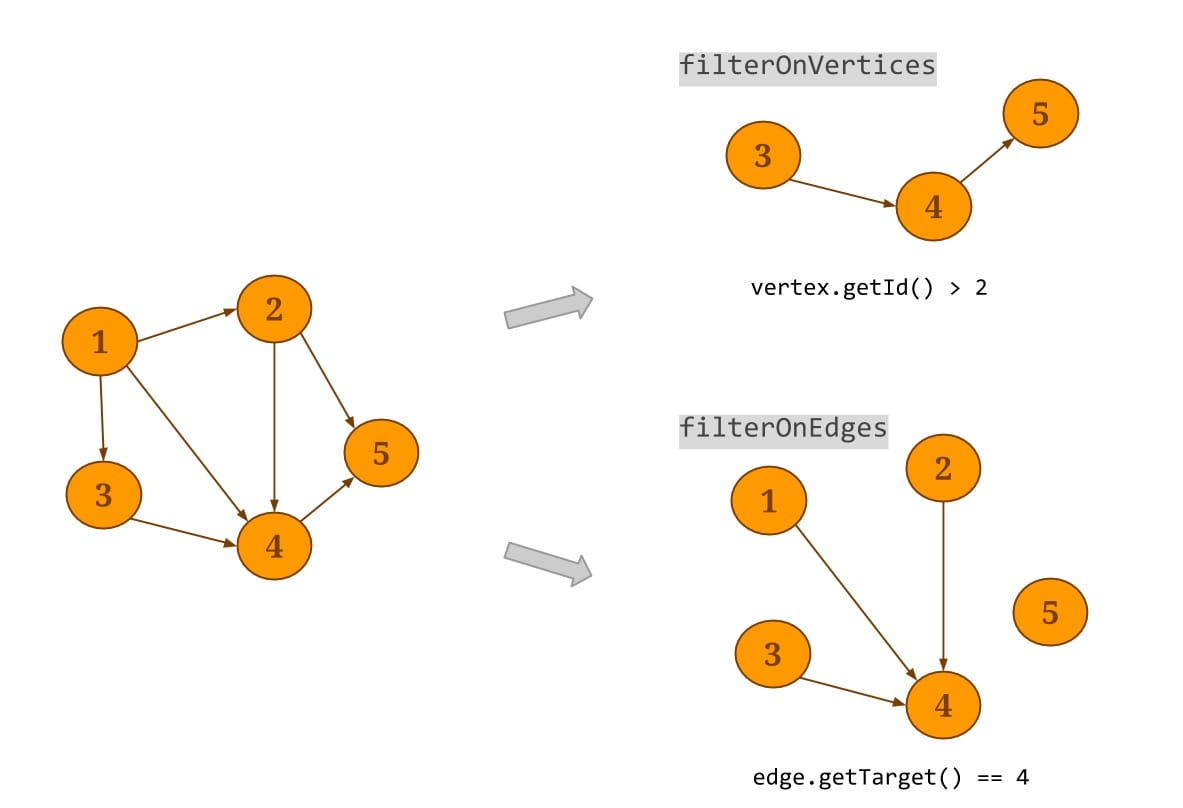
- Reverse:Gelly中得reverse()方法用于在原图的基础上,生成一个所有边方向与原图相反的新图。
- Undirected:在前面的内容中,我们提到过,Gelly中的图通常都是有向的,而无向图可以通过对所有边添加反向的边来实现,出于这个目的,Gelly提供了getUndirected()方法,用于获取原图的无向图。
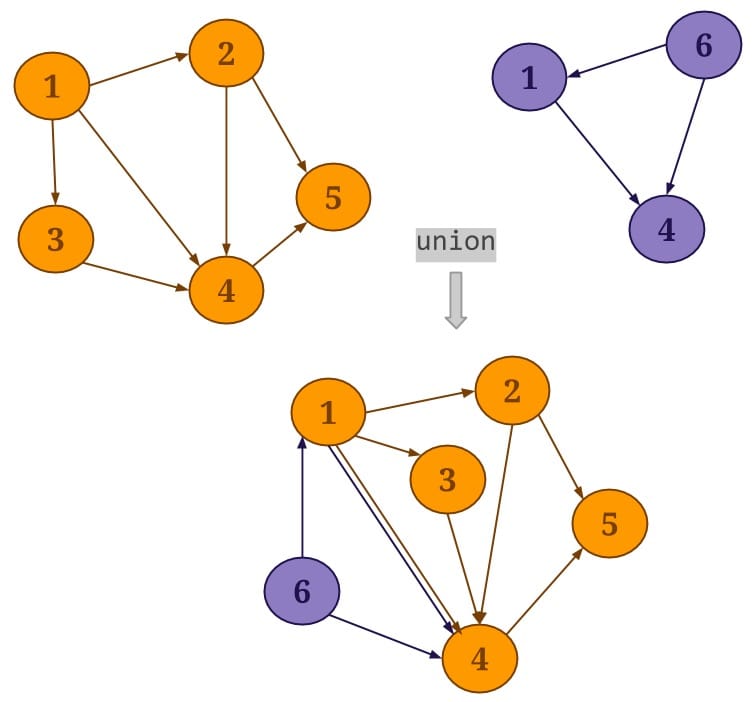
- Union:Gelly的union()操作用于联合当前图和指定的输入图,并生成一个新图,在输出的新图中,相同的节点只保留一份,但是重复的边会保留。如下图所示:
- Difference:Gelly提供了difference()方法用于发现当前图与指定的输入图之间的差异。
- Intersect:Gelly提供了intersect()方法用于发现两个图中共同存在的边,并将相同的边以新图的方式返回。相同的边指的是具有相同的源顶点,相同的目标顶点和相同的边值。返回的新图中,所有的节点没有任何值,如果需要节点值,可以使用joinWithVertices()方法去任何一个输入图中检索。
Graph 变化
Gelly 内置下列方法以支持对一个图进行节点和边的增加/移除操作:
1 | Graph<K, VV, EV> addVertex(final Vertex<K, VV> vertex) |
Neighborhood Methods
Graph 验证
6.5.4 小结与反思
加入知识星球可以看到上面文章:https://t.zsxq.com/nMR7ufq

本章所讲的内容属于 Flink 的扩展库,包含了 CEP 复杂事件处理、State Processor API、Machine Learning 和 Gelly,各种都有讲解一些样例,但是没有过多深入的讲,但还是希望你可以在书本外自己去扩充这些内容的知识点。


