
11.3 如何利用 Async I/O 读取告警规则?
Async 中文是异步的意思,在流计算中,使用异步 I/O 能够提升作业整体的计算能力,本节中不仅会讲解异步 I/O 的 API 原理,还会通过一个实战需求(读取告警规则)来讲解异步 I/O 的使用。
11.3.1 为什么需要 Async I/O?
在大多数情况下,IO 操作都是一个耗时的过程,尤其在流计算中,如果在具体的算子里面还有和第三方外部系统(比如数据库、Redis、HBase 等存储系统)做交互,比如在一个 MapFunction 中每来一条数据就要去查找 MySQL 中某张表的数据,然后跟查询出来的数据做关联(同步交互)。查询请求到数据库,再到数据库响应返回数据的整个流程的时间对于流作业来说是比较长的。那么该 Map 算子处理数据的速度就会降下来,在大数据量的情况下很可能会导致整个流作业出现反压问题(在 9.1 节中讲过),那么整个作业的消费延迟就会增加,影响作业整体吞吐量和实时性,从而导致最终该作业处于不可用的状态。
这种同步(Sync)的与数据库做交互操作,会因耗时太久导致整个作业延迟,如果换成异步的话,就可以同时处理很多请求并同时可以接收响应,这样的话,等待数据库响应的时间就会与其他发送请求和接收响应的时间重叠,相同的等待时间内会处理多个请求,从而比同步的访问要提高不少流处理的吞吐量。虽然也可以通过增大该算子的并行度去执行查数据库,但是这种解决办法需要消耗更多的资源(并行度增加意味着消费的 slot 个数也会增加),这种方法和使用异步处理的方法对比一下,还是使用异步的查询数据库这种方法值得使用。同步操作(Sync I/O)和异步操作(Async I/O)的处理流程如下图所示。
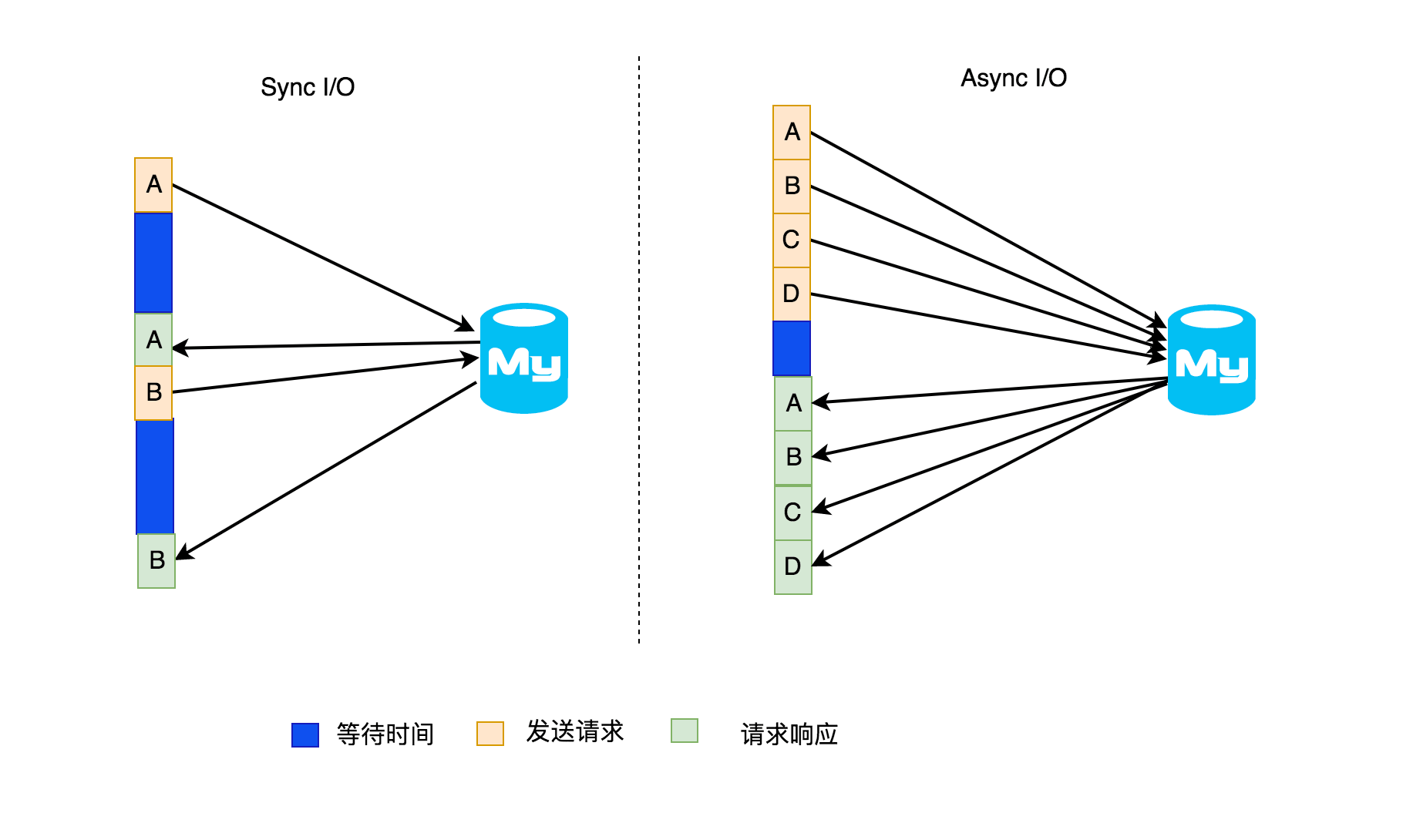
左侧表示的是在流处理中同步的数据库请求,右侧是异步的数据库请求。假设左侧是数据流中 A 数据来了发送一个查询数据库的请求看是否之前存在 A,然后等待查询结果返回,只有等 A 整个查询请求响应后才会继续开始 B 数据的查询请求,依此继续;而右侧是连续的去数据库查询是否存在 A、B、C、D,后面哪个请求先响应就先处理哪个,不需要和左侧的一样要等待上一个请求全部完成才可以开始下一个请求,所以异步的话吞吐量自然就高起来了。但是得注意的是:使用异步这种方法前提是要数据库客户端支持异步的请求,否则可能需要借助线程池来实现异步请求,但是现在主流的数据库通常都支持异步的操作,所以不用太担心。
11.3.2 Async I/O API
Flink 的 Async I/O API 允许用户在数据流处理中使用异步请求,并且还支持超时处理、处理顺序、事件时间、容错。在 Flink 中,如果要使用 Async I/O API,是非常简单的,需要通过下面三个步骤来执行对数据库的异步操作。
- 继承 RichAsyncFunction 抽象类或者实现用来分发请求的 AsyncFunction 接口
- 返回异步请求的结果的 Future
- 在 DataStream 上使用异步操作
官网也给出案例如下:
1 | class AsyncDatabaseRequest extends RichAsyncFunction<String, Tuple2<String, String>> { |
注意:ResultFuture 在第一次调用 resultFuture.complete 时就已经完成了,后面所有 resultFuture.complete 的调用都会被忽略。
下面两个参数控制了异步操作:
- Timeout:timeout 定义了异步操作过了多长时间后会被丢弃,这个参数是防止了死的或者失败的请求
- Capacity:这个参数定义可以同时处理多少个异步请求。虽然异步请求会带来更好的吞吐量,但是该操作仍然可能成为流作业的性能瓶颈。限制并发请求的数量可确保操作不会不断累积处理请求,一旦超过 Capacity 值,它将触发反压。
超时处理
结果顺序
事件时间
容错性保证
实践技巧
注意点
11.3.3 利用 Async I/O 读取告警规则需求分析
监控数据样例
告警规则表设计
告警规则实体类
11.3.4 如何使用 Async I/O 读取告警规则数据
11.3.5 小结与反思
加入知识星球可以看到上面文章:https://t.zsxq.com/RBYj66M



