线程池 Wiki 上是这样解释的:Thread Pool
作用:利用线程池可以大大减少在创建和销毁线程上所花的时间以及系统资源的开销!
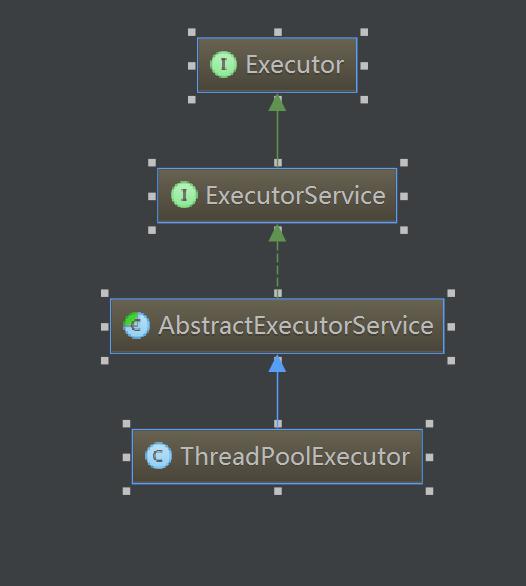
下面主要讲下线程池中最重要的一个类 ThreadPoolExecutor 。
ThreadPoolExecutor
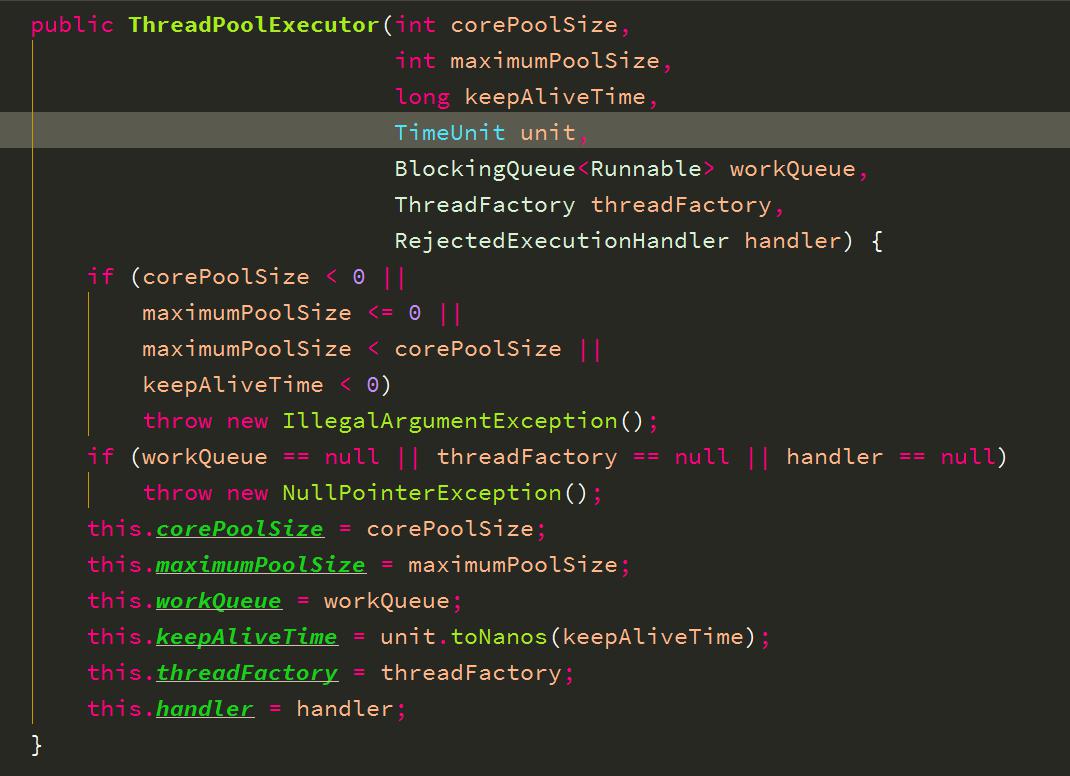
ThreadPoolExecutor 构造器:
有四个构造器的,挑了参数最长的一个进行讲解。
七个参数:
corePoolSize:核心池的大小,在创建了线程池后,默认情况下,线程池中并没有任何线程,而是等待有任务到来才创建线程去执行任务,当有任务来之后,就会创建一个线程去执行任务,当线程池中的线程数目达到corePoolSize后,就会把到达的任务放到缓存队列当中;
maximumPoolSize:线程池最大线程数;
keepAliveTime:表示线程没有任务执行时最多保持多久时间会终止;
unit:参数keepAliveTime的时间单位(DAYS、HOURS、MINUTES、SECONDS 等);
workQueue:阻塞队列,用来存储等待执行的任务;
ArrayBlockingQueue (有界队列)
LinkedBlockingQueue (无界队列)
SynchronousQueue
threadFactory:线程工厂,主要用来创建线程
handler:拒绝处理任务的策略
AbortPolicy:丢弃任务并抛出 RejectedExecutionException 异常。(默认这种)
DiscardPolicy:也是丢弃任务,但是不抛出异常
DiscardOldestPolicy:丢弃队列最前面的任务,然后重新尝试执行任务(重复此过程)
CallerRunsPolicy:由调用线程处理该任务
重要方法:
execute():通过这个方法可以向线程池提交一个任务,交由线程池去执行;
shutdown():关闭线程池;
execute() 方法:
注:JDK 1.7 和 1.8 这个方法有点区别,下面代码是 1.8 中的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public void execute (Runnable command) if (command == null ) throw new NullPointerException(); int c = ctl.get(); if (workerCountOf(c) < corePoolSize) { if (addWorker(command, true )) return ; c = ctl.get(); } if (isRunning(c) && workQueue.offer(command)) { int recheck = ctl.get(); if (! isRunning(recheck) && remove(command)) reject(command); else if (workerCountOf(recheck) == 0 ) addWorker(null , false ); } else if (!addWorker(command, false )) reject(command); }
其中调用了 addWorker() 方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 private boolean addWorker (Runnable firstTask, boolean core) retry: for (;;) { int c = ctl.get(); int rs = runStateOf(c); if (rs >= SHUTDOWN && ! (rs == SHUTDOWN && firstTask == null &&! workQueue.isEmpty())) return false ; for (;;) { int wc = workerCountOf(c); if (wc >= CAPACITY || wc >= (core ? corePoolSize : maximumPoolSize)) return false ; if (compareAndIncrementWorkerCount(c)) break retry; c = ctl.get(); if (runStateOf(c) != rs) continue retry; } } boolean workerStarted = false ; boolean workerAdded = false ; Worker w = null ; try { w = new Worker(firstTask); final Thread t = w.thread; if (t != null ) { final ReentrantLock mainLock = this .mainLock; mainLock.lock(); try { int rs = runStateOf(ctl.get()); if (rs < SHUTDOWN || (rs == SHUTDOWN && firstTask == null )) { if (t.isAlive()) throw new IllegalThreadStateException(); workers.add(w); int s = workers.size(); if (s > largestPoolSize) largestPoolSize = s; workerAdded = true ; } } finally { mainLock.unlock(); } if (workerAdded) { t.start(); workerStarted = true ; } } } finally { if (! workerStarted) addWorkerFailed(w); } return workerStarted; }
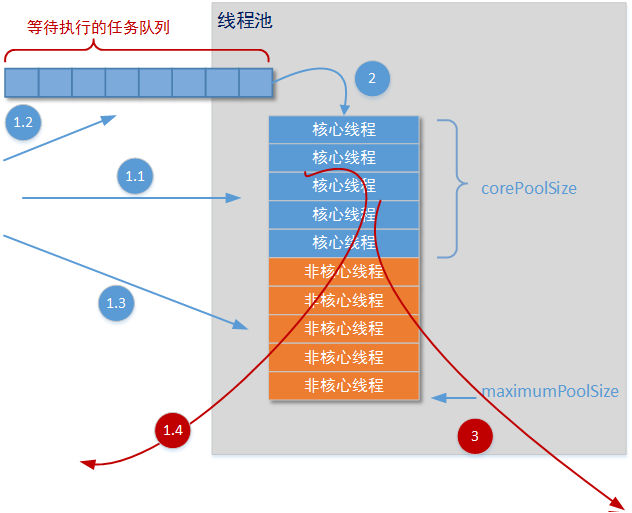
示意图:
执行流程:
1、当有任务进入时,线程池创建线程去执行任务,直到核心线程数满为止
2、核心线程数量满了之后,任务就会进入一个缓冲的任务队列中
当任务队列为无界队列时,任务就会一直放入缓冲的任务队列中,不会和最大线程数量进行比较
当任务队列为有界队列时,任务先放入缓冲的任务队列中,当任务队列满了之后,才会将任务放入线程池,此时会与线程池中最大的线程数量进行比较,如果超出了,则默认会抛出异常。然后线程池才会执行任务,当任务执行完,又会将缓冲队列中的任务放入线程池中,然后重复此操作。
shutdown() 方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public void shutdown () final ReentrantLock mainLock = this .mainLock; mainLock.lock(); try { checkShutdownAccess(); advanceRunState(SHUTDOWN); interruptIdleWorkers(); onShutdown(); } finally { mainLock.unlock(); } tryTerminate(); }
参考资料:深入理解java线程池—ThreadPoolExecutor
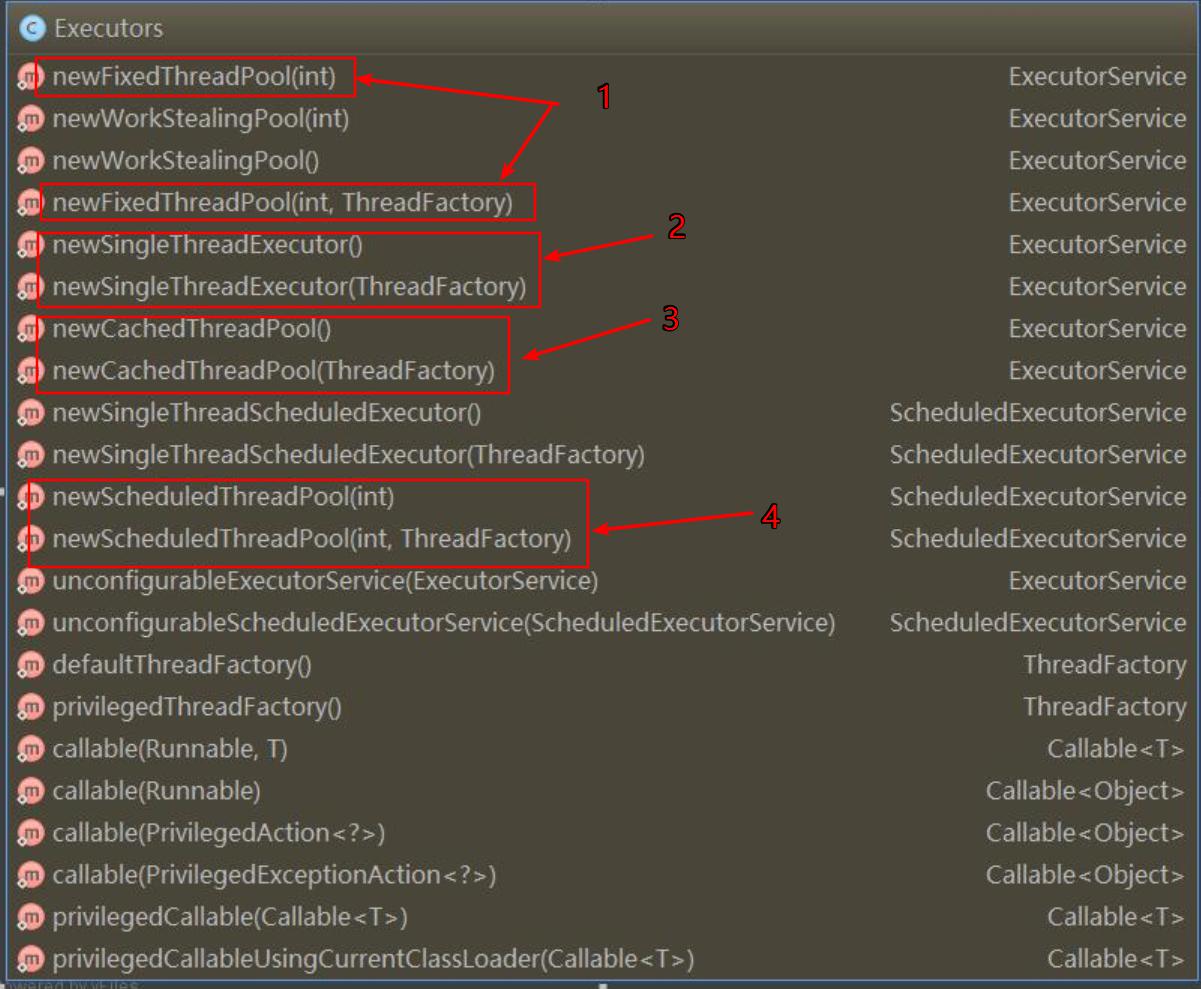
JDK 自带四种线程池分析与比较
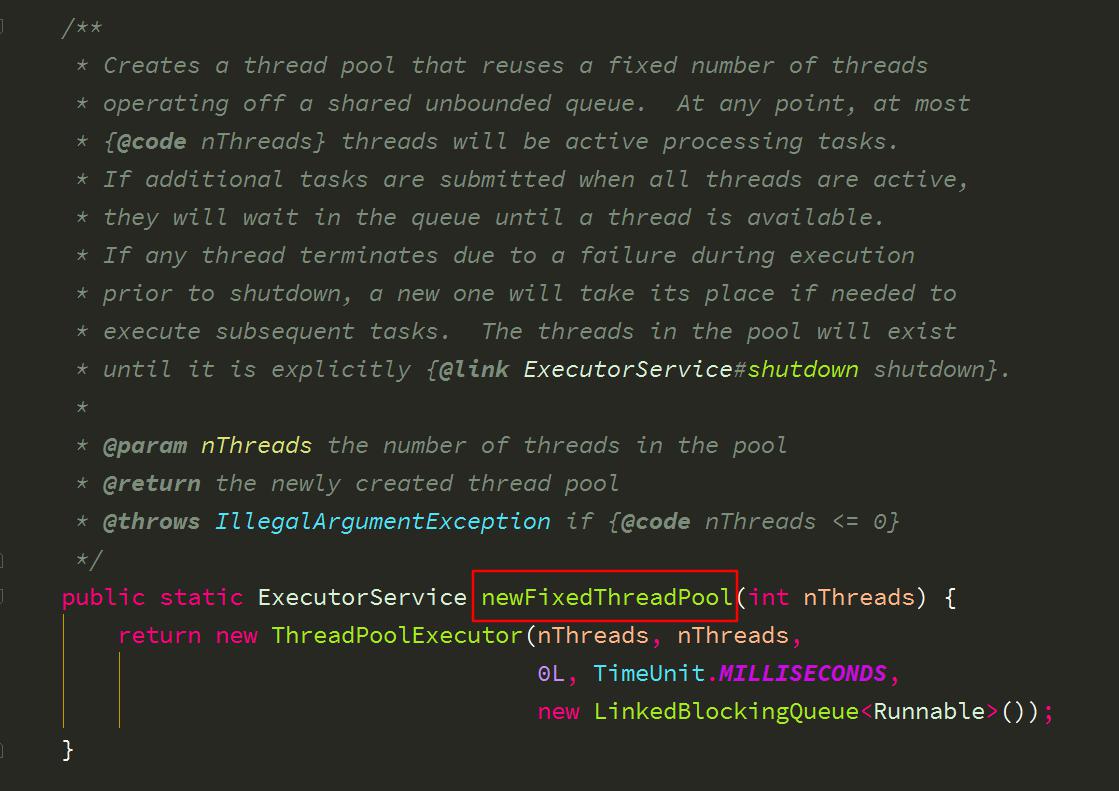
1、newFixedThreadPool 创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。
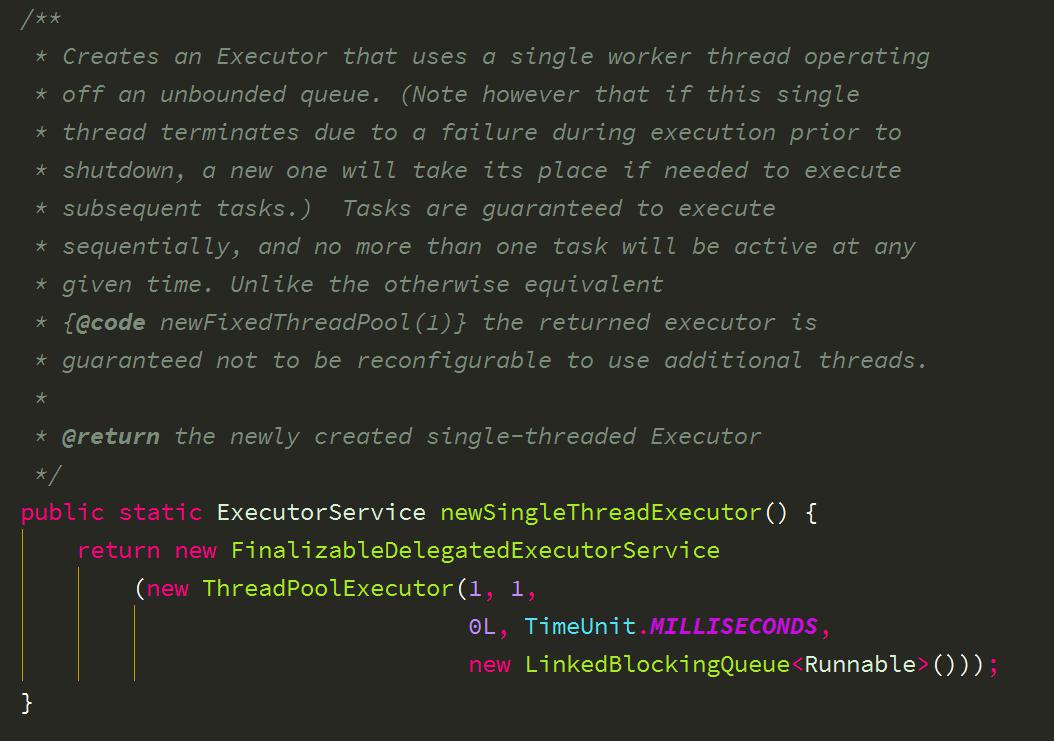
2、newSingleThreadExecutor 创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。
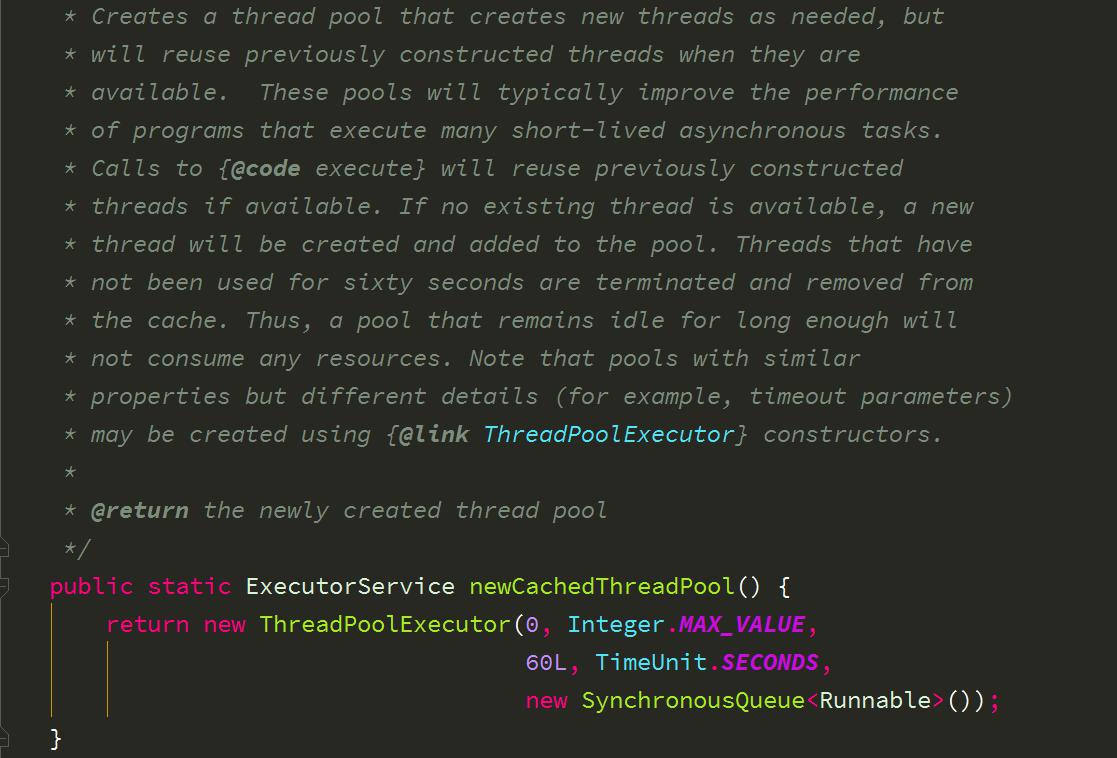
3、newCachedThreadPool 创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。
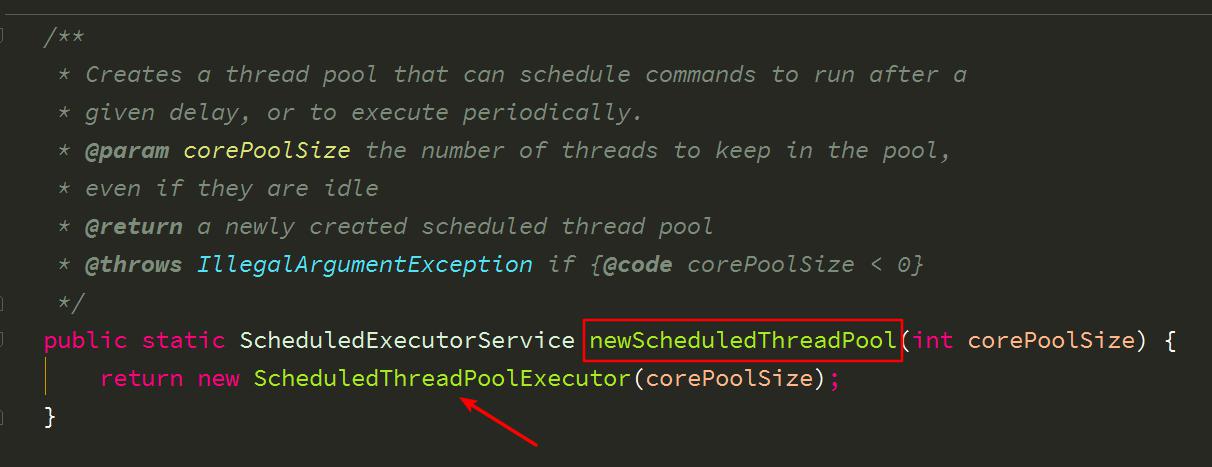
4、newScheduledThreadPool 创建一个定长线程池,支持定时及周期性任务执行。
四种线程池其实内部方法都是调用的 ThreadPoolExecutor 类,只不过利用了其不同的构造器方法而已(传入自己需要传入的参数),那么利用这个特性,我们自己也是可以实现自己定义的线程池的。
自定义线程池 1、创建任务类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 package com.zhisheng.thread.threadpool.demo;public class MyTask implements Runnable private int taskId; private String taskName; public int getTaskId () return taskId; } public void setTaskId (int taskId) this .taskId = taskId; } public String getTaskName () return taskName; } public void setTaskName (String taskName) this .taskName = taskName; } public MyTask (int taskId, String taskName) this .taskId = taskId; this .taskName = taskName; } @Override public void run () System.out.println("当前正在执行 ****** 线程Id-->" + taskId + ",任务名称-->" + taskName); try { Thread.currentThread().sleep(5 * 1000 ); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println("线程Id-->" + taskId + ",任务名称-->" + taskName + " ----------- 执行完毕!" ); } }
2、自定义拒绝策略,实现 RejectedExecutionHandler 接口,重写 rejectedExecution 方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 package com.zhisheng.thread.threadpool.demo;import java.util.concurrent.RejectedExecutionHandler;import java.util.concurrent.ThreadPoolExecutor;public class RejectedThreadPoolHandler implements RejectedExecutionHandler public RejectedThreadPoolHandler () } @Override public void rejectedExecution (Runnable r, ThreadPoolExecutor executor) System.out.println("WARNING 自定义拒绝策略: Task " + r.toString() + " rejected from " + executor.toString()); } }
3、创建线程池
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 package com.zhisheng.thread.threadpool.demo;import java.util.concurrent.ArrayBlockingQueue;import java.util.concurrent.ThreadPoolExecutor;import java.util.concurrent.TimeUnit;public class ThreadPool public static void main (String[] args) ThreadPoolExecutor pool = new ThreadPoolExecutor(2 , 4 , 60 , TimeUnit.SECONDS, new ArrayBlockingQueue<Runnable>(3 ), new RejectedThreadPoolHandler()); for (int i = 1 ; i <= 10 ; i++) { MyTask task = new MyTask(i, "任务" + i); pool.execute(task); System.out.println("活跃的线程数:" +pool.getActiveCount() + ",核心线程数:" + pool.getCorePoolSize() + ",线程池大小:" + pool.getPoolSize() + ",队列的大小" + pool.getQueue().size()); } pool.shutdown(); } }
这里运行结果就不截图了,我在本地测试了代码是没问题的,感兴趣的建议还是自己跑一下,然后分析下结果是不是和前面分析的一样,如有问题,请在我博客 下面评论!
总结 本文一开始讲了线程池的介绍和好处,然后分析了线程池中最核心的 ThreadPoolExecutor 类中构造器的七个参数的作用、类中两个重要的方法,然后在对比研究了下 JDK 中自带的四种线程池的用法和内部代码细节,最后写了一个自定义的线程池。